

Your AI project is probably failing now, and you don't even know it.
According to a 2024 McKinsey & Company report, only 26% of organizations using AI report seeing a significant bottom-line impact. Approximately 74% of AI initiatives fail to deliver their intended business value.
But here's what's interesting: Everyone blames the models.
In my opinion, they're wrong.
Recent findings from the Treblle Anatomy of an API report reveal that 52% of API requests have no authentication, 55% don't use SSL/TLS encryption, and 35% of endpoints are "zombie endpoints" - accessible but unmaintained. These security gaps create perfect vectors for attacks and data leaks that instantly kill AI projects.
Your infrastructure, specifically your APIs, is the silent killer of AI projects. API infrastructure issues don’t just slow down AI projects — they open the door to critical security vulnerabilities. Here’s a closer look at how the Model Context Protocol strengthens AI security by design.
The Hidden Crisis of API Debt
Technical debt is a familiar concept to most developers. You take shortcuts to ship faster, knowing you'll pay interest on that debt until you refactor the code properly.
API debt works similarly but with higher stakes and a bigger blast radius.
When Anthropic released Claude 3.5 Sonnet in April 2024, they introduced a Structured Context API to address context-handling problems. This move highlights that a proper API structure is critical for model performance and reducing hallucinations.
Models know plenty. Your API structure determines whether they can use that knowledge effectively.
Let's look at an example:
// What many developers send to an LLM API
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Analyze this customer feedback data to identify trends."},
{"role": "system", "content": "Here's the data: [200MB of unstructured text with mixed formatting]"}
]
}
That looks innocent enough. But this approach creates massive inefficiencies that compound with every call:
- You're sending unstructured or poorly structured data
- You're not providing schema information
- You're overloading contexts with redundant information
- You're not tracking request/response patterns to optimize
These inefficiencies directly tank your project's success metrics.
According to IBM's Global AI Adoption Index 2023, 44% of companies reported significant challenges with AI implementation related to data complexity and integration issues, leading to substantial project delays and budget overruns.
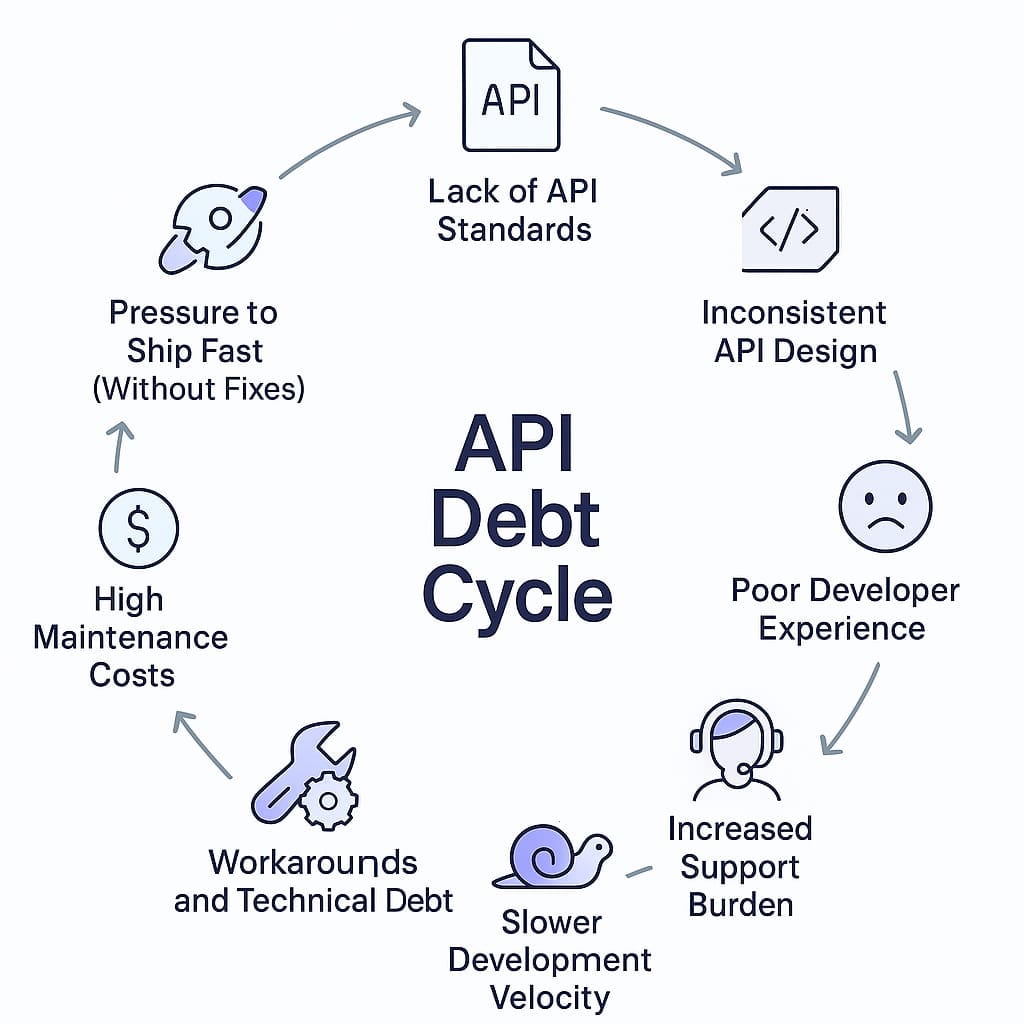
How API Debt Kills AI Projects
API debt follows a predictable failure pattern in production environments:
Phase 1: Quick Implementation
Your team implements basic API calls to LLMs. Everything works in demos. Leadership is excited. The project gets greenlit for production.
Phase 2: Scale Problems
As usage increases, your costs spike unexpectedly. Response times slow down. Hallucinations increase. Users start complaining about inconsistent answers.
Phase 3: Troubleshooting Loop
Your team assumes the model is the problem. You try a different model, but you have the same issues. You prompt the engineer. There is a temporary improvement. Problems return. You tune more parameters. There is no substantial improvement.
Phase 4: Project Death
After burning through budget and patience, the project gets labeled "AI isn't ready yet" and shelved.
It's so predictable that VCs now ask about API integration strategies before funding AI initiatives.
The Stanford HAI AI Index Report 2023 confirms this pattern, highlighting that integration with existing processes and systems remains among the top barriers to AI adoption. Data quality and preparation account for up to 80% of the time on AI projects.
These struggles aren’t unique — common API challenges in AI projects show up again and again, leading teams into the same trap of scaling issues, hallucinations, and budget overruns.
API communication deficiencies limit model performance. Fix your API strategy first.

Model Context Protocol: The Solution You Didn't Know You Needed
Look at the official documentation from any primary AI provider: Anthropic's "Structured Inputs" feature, OpenAI's "JSON mode," and Microsoft's "schema-driven outputs" are all solving the same problem - standardizing how data flows to and from AI models.
Model Context Protocol (MCP) formalizes these approaches into a comprehensive framework you can implement today, regardless of which AI provider you use. If you’re wondering how MCP compares to traditional API approaches, this article on MCP vs traditional APIs breaks it down clearly.
With MCP, you will implement:
- Standardized Schema Definitions: Define explicit JSON schemas for your data payloads before transmission to models.
- Context Management Rules: Separate system instructions, user queries, and persistent context into discrete API components.
- Observability Standards: Track token usage, latency metrics, and error patterns across all model interactions.
- Versioning Protocols: Implement versioning protocols for your API requests to ensure compatibility when model providers release updates.
In a case study detailed in Microsoft's Azure AI blog, implementing structured API protocols for their LLM services reduced latency by 35% and improved answer relevance by improving how context information was formatted and transmitted.
Similarly, in their article "Sidekick's Improved Streaming Experience", Shopify Engineering shared how refactoring their API calls with better context structure helped reduce unnecessary token usage and improve model response quality.
The 4 Pillars of Model Context Protocol
The NIST AI Risk Management Framework, released in January 2023, provides insights on structured data flows and integration patterns that align with the Model Context Protocol.
1. Data Structure Standardization
Define how to format data before sending it to the model API.
- JSON schema definitions for structured data
- Chunking strategies for large datasets
- Entity standardization across systems
Example of poor structure:
{
"data": "John contacted support on 4/15 about billing issue #4392. He was charged twice for his subscription on 4/10. His account is premium tier. His email is [email protected]."
}
MCP approach:
{
"ticket": {
"id": "4392",
"date": "2025-04-15",
"category": "billing"
},
"customer": {
"tier": "premium",
"contact": "[email protected]"
},
"issue": {
"description": "Double charge for subscription",
"date": "2025-04-10"
}
}
But structured data is just the start. Let's go deeper with a practical implementation:
// MCP middleware for standardizing API requests to LLMs
function prepareModelRequest(data, requestType) {
// Validate against predefined schemas
const validationResult = validateAgainstSchema(data, requestType);
if (!validationResult.valid) {
throw new Error(`Invalid data structure: ${validationResult.errors}`);
}
// Apply chunking for large text fields
const chunkedData = chunkLargeTextFields(data);
// Add metadata for tracking and observability
const requestWithMetadata = addRequestMetadata(chunkedData, requestType);
return requestWithMetadata;
}
This middleware ensures that every request follows your data standardization rules before reaching the model API.
2. Context Management
Establish rules for what information belongs where:
- System-level instructions vs. user queries
- Persistent context vs. conversation history
- When to reset context windows
Most developers make a mistake with context management. They dump everything into a single request rather than strategically managing what the model needs to know and when.
// Example of strategic context management
const contextManager = {
// Global system context that rarely changes
systemContext: {
modelBehavior: "You are a professional customer service assistant...",
dataSchemas: { /* schema definitions */ },
companyPolicies: { /* policy information */ }
},
// User-specific context that persists across conversations
userContext: new Map(),
// Active conversation history (limited to N messages)
conversations: new Map(),
// Construct the optimal context for a specific request
buildRequestContext(userId, conversationId, currentQuery) {
// Get or initialize user context
let userCtx = this.userContext.get(userId) || this.initializeUserContext(userId);
// Get conversation history (with size limits applied)
let conversationHistory = this.getConversationWithSizeLimits(conversationId);
// Determine what context is actually needed for this specific query type
const relevantContext = this.selectRelevantContext(currentQuery, userCtx);
return {
system: this.systemContext,
user: relevantContext,
history: conversationHistory,
current: currentQuery
};
}
};3. Request/Response Tracking
Monitor patterns in API interactions:
- Track token usage by request type
- Identify which formatting leads to better responses
- Log and analyze errors and hallucinations
Set up structured logging for every model interaction:
// tracking middleware
async function trackModelInteraction(request, modelProvider) {
const startTime = performance.now();
const requestTokens = countTokens(request);
try {
// Make the actual API call
const response = await modelProvider.complete(request);
// Record success metrics
const endTime = performance.now();
const responseTokens = countTokens(response);
// Log structured data about this interaction
await logModelInteraction({
timestamp: new Date(),
requestType: request.metadata.type,
latency: endTime - startTime,
requestTokens,
responseTokens,
cost: calculateCost(requestTokens, responseTokens, modelProvider.pricing),
success: true
});
return response;
} catch (error) {
// Log errors with context
await logModelInteraction({
timestamp: new Date(),
requestType: request.metadata.type,
requestTokens,
error: error.message,
success: false
});
throw error;
}
}4. Versioning Strategy
Prepare for model changes:
- Version your API requests
- Test new model versions with old request formats
- Establish migration paths for breaking changes
Developers often build AI implementations assuming models won't change. That's dangerously naive. Models are updating faster than ever, and each update can break your carefully tuned interactions. For a full breakdown of managing model updates, check out this guide on AI in API versioning and deprecation.
You need versioning at multiple levels:
// Request format versioning
const requestFormatters = {
"v1": (data) => { /* old formatting logic */ },
"v2": (data) => { /* current formatting logic */ },
"v3-beta": (data) => { /* experimental new format */ }
};
// Model version mapping
const modelVersionMapping = {
"gpt-3.5-turbo": { defaultFormatter: "v1", fallbacks: ["v2"] },
"gpt-4": { defaultFormatter: "v2", fallbacks: ["v1"] },
"claude-3-opus": { defaultFormatter: "v2", fallbacks: ["v2-claude"] }
};
// Adaptive request formatter that tries the preferred format first
// but can fall back to compatible formats if needed
async function createAdaptiveRequest(data, targetModel) {
const modelConfig = modelVersionMapping[targetModel];
try {
// Try the default formatter first
const formattedRequest = requestFormatters[modelConfig.defaultFormatter](data);
return formattedRequest;
} catch (error) {
// Log the failure
console.error(`Primary formatter failed: ${error.message}`);
// Try fallback formatters
for (const fallbackVersion of modelConfig.fallbacks) {
try {
console.log(`Attempting fallback formatter ${fallbackVersion}`);
const fallbackRequest = requestFormatters[fallbackVersion](data);
return fallbackRequest;
} catch (secondaryError) {
console.error(`Fallback formatter ${fallbackVersion} failed: ${secondaryError.message}`);
}
}
// If we get here, all formatters failed
throw new Error("Unable to format request for model " + targetModel);
}
}Getting Started with MCP
Start implementing MCP with your existing development stack using these technical steps:
- Audit Your Current API Calls: Extract and analyze your API call patterns from logs. Identify token usage patterns, redundant information, and unstructured data fields.
- Document Your Schemas: Create explicit JSON Schema definitions for each data type. Version these schemas and store them in your code repository.
- Implement Basic Tracking: Add instrumentation code to log token counts, latency metrics, error types, and cost per request category.
- Refactor Incrementally: First, target endpoints with the highest token consumption or error rates. Measure performance improvements after each refactoring cycle.
According to Gartner's research on responsible AI implementation, organizations with mature AI governance practices reported fewer critical incidents and achieved positive ROI faster than those without structured governance frameworks.
The Hard Truth About Your AI Architecture
Most companies building AI applications are doing it wrong.
They think the model is the show's star, but it's not. The model is just one component.
Your API architecture: How you prepare data, manage context, handle responses, and adapt to changes separates the companies seeing real value from AI from the 74% that are failing.
Teams that embrace an API-First mindset — prioritizing communication and structure over flashy models — are consistently outperforming those that don’t.
While everyone else is chasing the latest model or prompt engineering technique, you must fix your foundation.
The Future of AI is API-First
The differentiator for successful AI implementations in 2025 will not be which model you use but how effectively you communicate with it.
As models become more capable, your API strategy becomes more critical, not less. Better models can do more with better inputs and get more confused with poor ones.
The next time your AI project faces challenges, don't immediately blame the model or rush to prompt engineering. Look at your API implementation. Your API debt might be the hidden reason your AI strategy is failing.
And if you want your AI strategy to succeed while your competitors struggle with the basics, prioritize Model Context Protocol before your API debt compounds beyond recovery.
The most successful AI implementations I've seen have one thing in common: disciplined, structured API management. It's not sexy and doesn't make for good conference talks, but it works.




