
Not that long ago I wrote this blog post about how we scale Treblle on AWS without burning thousands upon thousands of dollar bills per month. At that time I didn’t expect to write about scaling for at least 6 months to a year. But, it turns out, I’m going to have to make this into a series of articles 😂
While thinking about the title for my series I remembered a book I always saw in the bookstores. I’m not an avid book reader, but I do have a fiance who is. In translation for everyone who doesn't have a fiance yet, that means I’m in bookstores a lot 🙃 I wonder around, look at the comics section and scan pretty book covers. The covers that always caught my attention were the ones from a book series called Diary of a wimpy kid. They’re funny, memorable and seem like they would be a good read. All noble qualities I’d like for my very own series. Hence the title: “Diary of a wimpy DevOps engineer” 🥁
Regular readers know that I usually spend quite some time looking for a song that matches the article. This time the song basically spoke to me before I wrote down a single word. It’s a remake of Burning down the house by Tom Jones and The Cardigans. Great vibes. Great song. Let’s do it…
A bit of context
When I originally developed Treblle I designed it to be a singular, majestic and beautiful monolith. Yes, yes I know...But at that time I was the only guy working on it. I knew the code like the back of my hand. I could visualize the lines numbers and functions when I would close my eyes. But, with time, it got bigger. More complicated. Diverse. We introduced more features, added an entire API layer for the mobile apps and, given we’re a SaaS company, a ton of transactional emails 😜 Also, to be perfectly honest, at that time I didn’t know how to efficiently share code between microservices. So many questions were popping into my head. What should be a microservice and what should not? What will need to be reused? How to update and maintain reusable code? All good questions but quite difficult ones. The one thing I learned in my career is that there is always a time and place for those kinds of questions but we simply weren’t there, yet. Complicating things before you even get started is the definition of every side project many of us start but never see the light of day. I wasn’t going to allow that to happen with my monolith so I simply prolonged answering them 😂
Time passed. We hired more developers and they started working on the monolith. We also grew. A lot. Like, really a lot. In the past 4 months we on-boarded more than 9000 developers across 3200 different APIs making about 44M API calls per month. The problems we started noticing at this scale were not quantity related but rather pace related. Any decent infrastructure can handle this quantity and then some but the problems become more apparent when you try to handle all those API requests in real-time. We get hit by 100 000 API requests from 10 different APIs in the span of a few minutes. On top of that our customers are on the website waiting to see the requests as they happen. In real-time. Which is the whole point of Treblle. Not 5 minutes later or an hour later or that afternoon. Now. This second. Instantly.
Before we continue I'd like to note one important thing:
We figured that part before we even launched and never had a problem with it. The slowdowns I’m describing happen long after we’ve gotten the data from you and your API is off doing other happier things.
The reason for the slowdowns was our ETL process. We take the RAW data from your API and make it rich, beautiful and useful. We try to understand your API on a micro level as well as the macro level and it starts with a single request. Amongst the things we do are: convert IP to location, detect OS and app information, generate endpoints and docs for your API, extract and store analytical data, test your API for best practices…In short - we do a lot and we’ll be doing even more. All of that, simply put, takes time. No other way around that.
With my little monolith we were clocking at around 550ms to process a single API request - from start to finish. Considering everything we do, that was good but not great. The limitations we were facing weren’t actually infrastructure related - far from it. We run serverless using Laravel, Laravel Vapor and AWS Lambda. We also use AWS SQS a lot to process jobs in the background and the scale there is simply amazing.
I’ve noted in one of my previous articles that 9 out of 10 times when there are scaling issues the problem is in the database. I knew that at the end of this journey we'll need to solve the MYSQL problem. We were using AWS RDS for MYSQL which is great but I literally had to scale it every 3 days. Given the amount of API requests we were processing the entire system would simply become sluggish, slow and cumbersome. All words I dread hearing.
But before we take care of the hard stuff let's first figure out what to do with my monolith.
Breaking down the monolith
Every monolith is specific, or at least we like to think that. Without knowing what your product does I bet you have an API, a UI layer or two, some business logic and maybe throw emailing or a payment service. Well, guess what? We all have those! This means that we all have the same problems and many before us have solved these problems. Learn from others because we're more alike than any of us would like to admit. I’ve seen so many get stuck trying to determine what should be a microservice and what shouldn't. They either overcomplicate or oversimplify. We’ve all been there and done that. It’s the curse of a developer. You always think that someone else missed something or that you can do better. So to help myself, and all of you, I’ve boiled down the decision process of what should/shouldn’t be a microservice into 3 questions:
- Will I need to scale this part of the monolith more (often) than others?
- Does this part of the monolith handle an entire process on its own from start to finish?
- Does this part of the monolith require a lot of different code or resources than the other parts?
The questions are simple. They aren't philosophical. They don’t have a hidden meaning. Rather, a series of simple booleans. If something needs to be a microservice it'll most likely hit 3 out of 3 of those. A trifecta. A hat trick. A three true outcomes.
The best way to test my thesis is to take a look at how I broke down my Rosie. Yes, with time the monolith got a name. Hence destroying it is emotional. And yes, it's from that AC/DC’s song 🤘
Pipeline
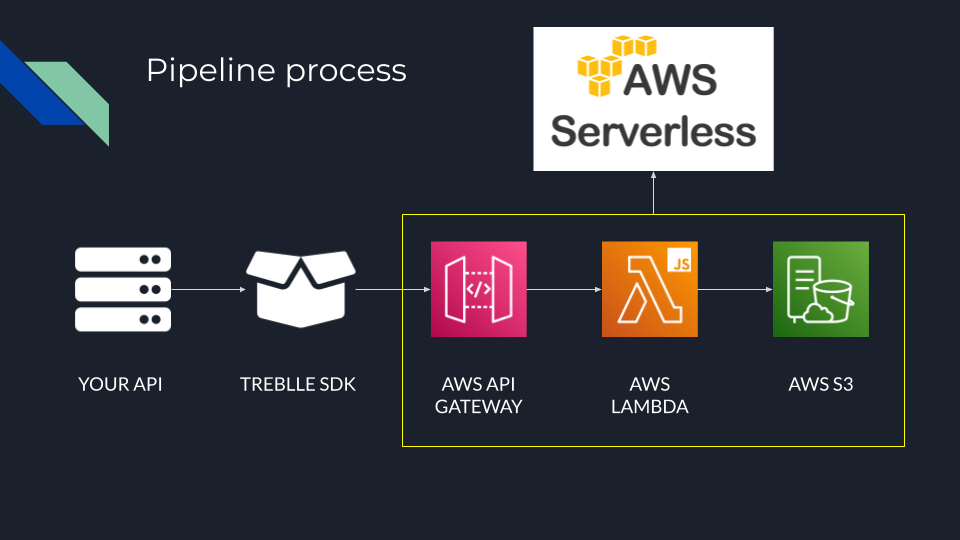
The first part of the Treblle platform is what we internally call the pipeline. It takes the RAW data from the SDKs and stores it into an S3 bucket. The description of the process I just wrote literally answers question number 2. It does one single thing from start to finish, on its own.
Knowing that this is the most intense part of our platform means we'll probably need to scale it more often and give it more firepower. That answers question number 1.
Finally, the code base which is, by the way, around 7 lines of JavaScript and a few AWS services meshed together are completely different from the rest of the platform. In every other part we use PHP, Laravel and here it’s pure JS. With this we answer question number 3.
Like I told you - hat trick. Deserves its own microservice.
ETL
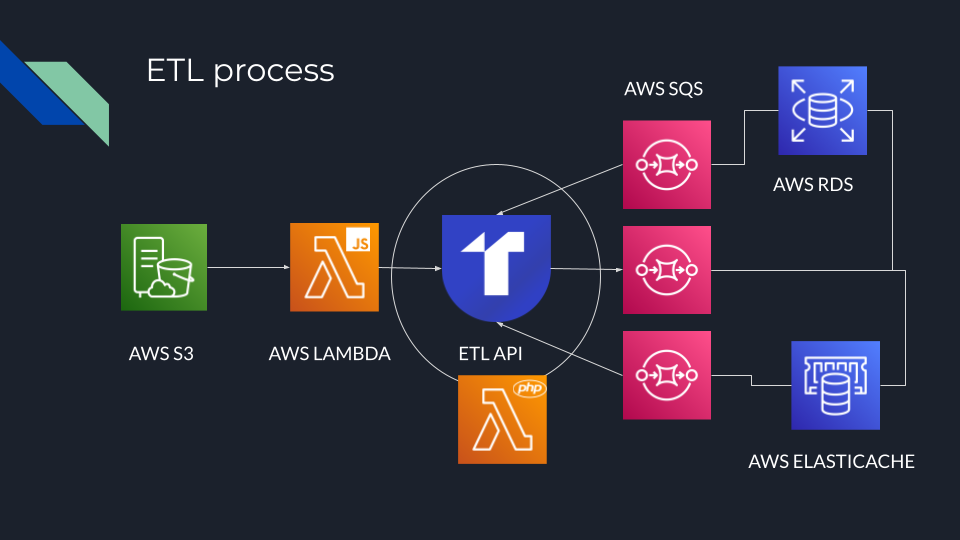
The ETL part, as the name implies, does one thing. That one thing is complicated, but still one thing. It takes the RAW data from the file, transforms it, enriches it and stores it into a database. Again, we answered question number 2 here. The ETL is a self contained part that is in charge of taking the data and preparing it for our customers.
The ETL is literally next in line after the pipeline in terms of scaling. Every single API request passes through here which means it is quite important and it needs to scale as much as possible. Just answered question number 1 for us.
Finally the code base for this ETL is nothing like the API, website or platform code base. Yes it might share a couple of components but fundamentally ETL code is different. This code also needs to be highly optimized. And I do mean highly. That gives us the answer to question number 3.
Definitely microservice worthy.
API
Our beloved API. It, for now powers, all our native applications for iOS, iPad, MacOS and Android. When we look at it through our "does it deserve to be a microservice" framework it looks like this.
Question 1: we might need to scale it more in the future but not right now. This means that right now we can run it for pennies on the dollar and give it more power if needed.
Question 2: An API is the brains of the the entire operation but also at the end of the day it's job is to exchange information between a client and a database. It uses a pretty specific language called JSON. One could say that the API does something on enclosed, from start to finish.
Question 3: The code base we use for the API is quite different from the rest of the platform. Yes, it’s developed using PHP and Laravel but it’s focus is more on providing resources and models in JSON. It’s also very limited unlike the rest of the platform in terms of permissons. So instead of building a very complicated permission schema for 3 different parts we have the luxury of building a specific one for our API.
An API has always been and always will be a prime microservice candidate and this time it's no different
Website
Websites are very near and dear to my heart. I’ve built hundreds of them over the years and the part that I like the most is optimizing them. Taking a page that loads for 2 seconds down to maybe like 300ms is so rewarding to me. Much more than it should be. But it is for some reason.
In terms of scaling and question number 1, again this part might need to be separately scalable from the rest. Why? Because it’s the first jumping point for the rest of the system. If someone wants to use Treblle they'll first come to the website.
As far as question number 2 goes: the website is literally in charge of one thing only. It explains to our customers what it is that we do. It’s a pretty picture, if you will, and does not depend on anything else.
Question number 3 about the code base. It is using PHP and Laravel but also a lot of CSS/JS. Things we don’t use anywhere else but the website and the platform. The key difference between the website and the platform is the design. It’s not the same which means we can have a huge code base for both of them together or we can separate them out. Given that they do different things - we opted for separating them out.
To my surprise - microservice ready.
But here comes the twist. Recently I've had to think more as a founder and CEO than a developer about some of the things we're working on. Who does what, where is the energy spent... Given the singular purpose of the website is sales and marketing, in my opinion, it should be controlled by those teams. Traditionally that means we have to go more towards a no-code or less code solution if you will. Sentences like that make me cry as a developer but given that we need to move faster I’ve decided to let go of some of the control here and use Webflow. Why Webflow? It’s simple. Great templates. I don’t mean that just in a design sense of the way but actually in terms of the HTML and CSS code. Much better than what I expected. So our new website is actually going to be Webflow based and fully in control of teams that prefer number over beautifully written code 😂.
Platform
The final part of our platform is the platform itself 😊. This is where you login, view your dashboard and actually see all the information about your APIs.
As far as question number 1 one goes: does it need to be scalable more than the other parts? Yes, absolutely. We know it'll be used by all our customers and also it'll be handling all interactions with the database. Hence we'll probably need to scale this a bit differently than our website or the API.
Question number 2, does it handle an entire process on its own. Absolutely.
Question number 3, does it have a different code base than the other parts. In theory it could share some of the code base with our website but given it has a different design language and purpose the code base is going to be somewhat different. Still PHP/Laravel and HTML/CSS/JS but the HTML/CSS/JS part will look completely different from the website.
Again. A new microservice.
That's it, we covered all them. It was suprising that’s how easy it was to break down my good old Rosie. I spent probably around a year writing bits and peaces of that code and it was time to re-invent it. Better. Stronger. Faster. Which in my opinion is the true purpose of a developer and peace of software.
One thing that I wanted to mention is this notion of third party microservices. What do I mean by that? Well, extracting a part of your platform and using an open source system or a SaaS solution for it. The first candidate in our case is the very blog you’re reading this on. We had a choice of either developing something on our own which would take us months or using an off the shelf solution. That’s exactly what we did. We separated the blog to its own subdomain, blog.treblle.com and connected it to Ghost. Great blogging platform. Plethora of features, stats and everything we needed.
We also did this with the payments part of our website. It's using Stripe end to end. Not a single line of code regarding payments is handled by us which is amazing and makes me sleep better at night. We'll probably do this with a couple of other parts like the knowledge base, FAQ, emailing and developer docs.
To sum it up, microservices should make things simpler and easier, not more complicated. Let that guide you through the process.
Now let’s take a look at how to share things across multiple different microservices.
Sharing code across microservices
I knew that before we broke down my Rosie we needed to figure out how we can share code between different microservices. Logically the first place to start would be the database layer. In Laravel that means models, migrations and seeders. By default all Laravel models have a namespace of App/Models (which means they sit in a folder app/models). On the other hand all migrations can be found in a folder called database/migrations. If you’re not familiar with migrations it’s a really cool way of defining a database schema using code. Basically, instead of writing SQL commands like CREATE TABLE you use built in Laravel capabilities and define the entire structure for each of the tables in its own file using code. Amazing feature because that then gets committed into GIT and you know who changed what. To run the migrations you just type in php artisan migrate and Laravel will go through all the files and translate the code you wrote into SQL queries and execute them. It'll know what migrations you ran before and which are new so you don’t have to worry about deleting data from an existing database.
If we are going to have multiple different microservices they all need to have the same models, migration files and seeders in order to talk to the database. The simplest way is to keep copy/pasting them constantly. But hey, we are developers here, are we not? Simple things like that are not a part of the job description - so we complicate 😀. The only other alternative is to build a package that you can install via Composer as a dependency. That’s more like it. Now, Composer is a packaging system (for all the cool kids out there - something like NPM) for PHP as well as the best thing that happened to modern day PHP. I did have some experience building a package because I built the original SDKs for Treblle - but they were public. This puppy needed to be private, of course. That makes things a bit more complicated.
To make a private composer package you start by making a private GIT repository. Just like everyone else we use Github so there are some prerequisites that need to be done there. You’ll need a Personal access token which you can get under Settings and then Security on Github. This step is quite important because that token will actually allow Composer to access the repo and download the latest version of the package. Take the token you got and create a new file called “auth.json” with this content:
{
"github-oauth": {
"github.com": "_YOUR_TOKEN_HERE_"
}
}Store the file in the root directory of your Composer project (Laravel project) and forget about it. We’ll use this file later on to be able to install our custom private Laravel package into other microservices.
Now it's time to we build our Laravel database package. Every package starts with a definition in Composer where we define our dependencies, auto-loaded files and providers. Here is our actual composer.json:
{
"name": "treblle/treblle-database",
"description": "Shared database components for Treblle",
"keywords": [
"treblle",
"models",
"database",
"migrations",
"seeders"
],
"homepage": "https://treblle.com",
"license": "MIT",
"authors": [
{
"name": "Vedran Cindrić",
"email": "[email protected]",
"homepage": "https://treblle.com",
"role": "Developer"
}
],
"require": {
"php" : "^8.0|^8.1",
"illuminate/database": "^8.0|^9.0"
},
"require-dev": {
"phpunit/phpunit": "^9.4"
},
"autoload": {
"psr-4": {
"Treblle\\Database\\": "src"
}
},
"autoload-dev": {
"psr-4": {
"Treblle\\Database\\Test\\": "tests"
}
},
"extra": {
"laravel": {
"providers": [
"Treblle\\Database\\DatabaseServiceProvider"
]
}
},
"scripts": {
"test": "phpunit"
},
"config": {
"sort-packages": true
},
"minimum-stability": "dev",
"prefer-stable": true
}As you can see we do have a Service provider called DatabaseServiceProvider. These are VERY important for Laravel packages as they are the ones that enable your custom code to run inside Laravel. Our Service provider is super simple:
<?php
namespace Treblle\Database;
use Illuminate\Support\ServiceProvider;
class DatabaseServiceProvider extends ServiceProvider
{
public function boot()
{
$this->loadMigrationsFrom(__DIR__.'/../database/migrations');
}
public function register()
{
}
}It simply loads our custom migrations and enables you to use them while running php artisan migrate. To make things more visual for you, here is how the package is structured.
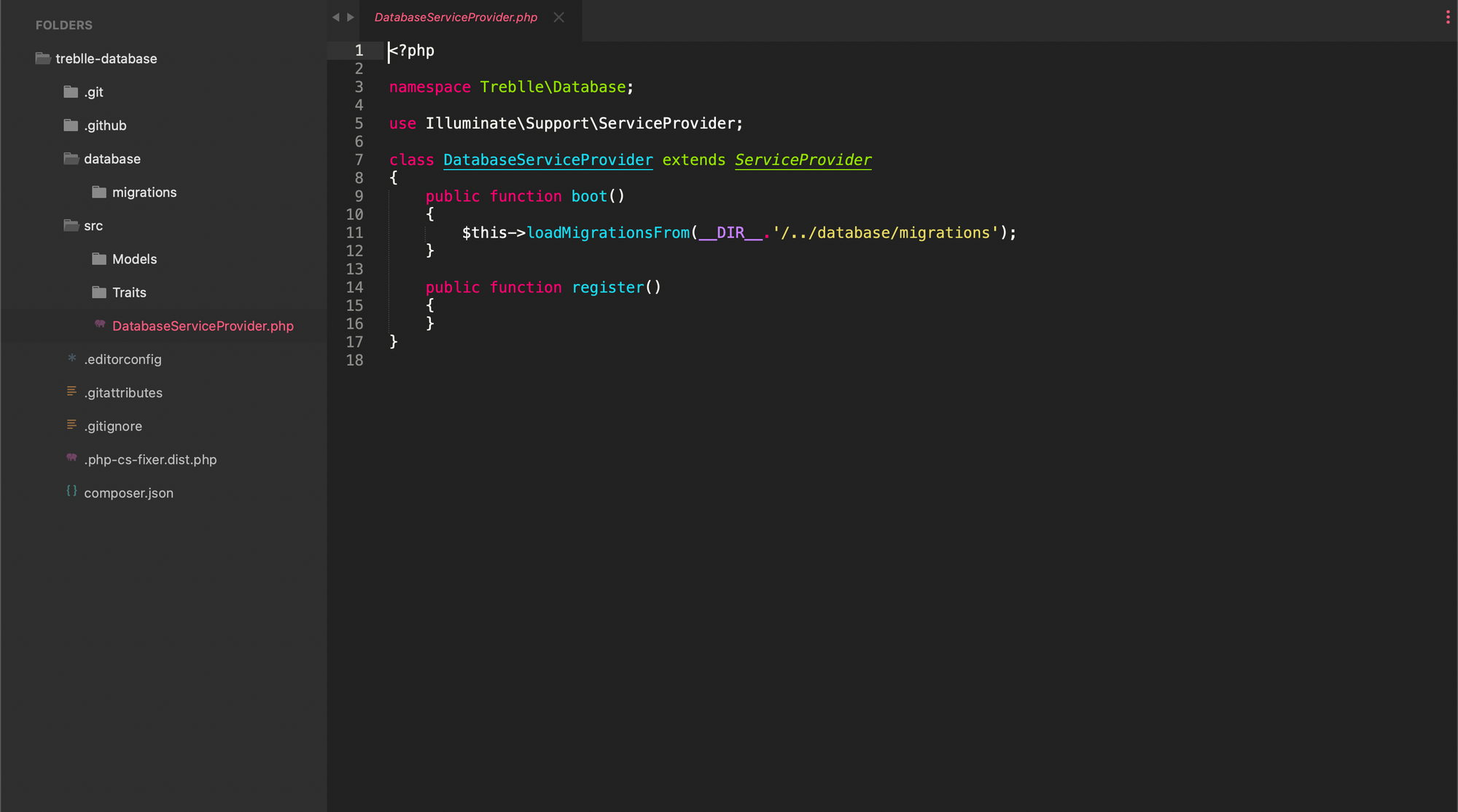
All the migrations are located in a folder database/migrations because we are follwing Laravel naming and structing conventions here. Then we have a folder src with our service provider as well as a Models and Traits folder. The names should be self-explanatory but in case you missed it Models houses all our actual Laravel database model definitions and Traits are our custom helper classes for various things. If we want to use the models defined in our package we need to make sure we are using the correct namespace of: Treblle\Database\Model.
<?php
namespace Treblle\Database\Models;
use Illuminate\Database\Eloquent\Model;
class Post extends Model
{
public function user()
{
return $this->belongsTo('Treblle\Database\Models\User');
}
public function comments()
{
return $this->hasMany('Treblle\Database\Models\Comments');
}
}That's it. That's all it actually takes to build a custom Laravel package for your database. But before we wrap up I really want to show you a cool trait we’re using with the package. It was implemented by Akhil, our back-end dev, so all kudos to him.
Most of our tables have a UUID on them - without getting too much into the why let’s just agree that they are much safer to use than IDs 😂. Alongside UUIDs there are also various random string based keys that we have to create each time we’re storing things into a table. Well this trait makes our life a lot easier by automatically creating a UUID or a random token for specific tables upon creation. It uses Eloquent database events and listens for the “creating” event and appends a UUID if it’s not already defined. For some other tables it adds a few other things as well. And to top it all off, Akhil created a special function that can be called on any Eloquent model to find a specific item by UUID, so we don’t have to write all those custom WHERE queries every time.
<?php
namespace Treblle\Database\Traits;
use Carbon\Carbon;
trait TreblleModelDefaults
{
public static function bootTreblleModelDefaults() :void
{
static::creating(function ($model) {
$model->uuid = $model['uuid'] ? $model['uuid'] : str()->uuid()->toString();
match ($model->getTable()) {
'users' => $model->api_key = str()->random(32),
'projects'=> $model->custom_id = str()->random(16),
default=>'unknown',
};
});
}
public static function findByUuid($uuid)
{
$instance = new static;
return $instance->newQuery()->where('uuid', $uuid);
}
}Now that we have a sharable, database package for Laravel we can actually go figure out our database situation.
Replacing RDS with SingleStore
So far we’ve been dancing around this but it’s finally time to solve the mother of all scaling problems - MYSQL. I’m a huge fan of MYSQL and have been using it for the better part of 15 years. I’ve seen all sides of it: the good, the bad and the ugly. Despite the flaws I’d still pick MYSQL over any database any time of day. It’s widely supported, it’s battle tested, the syntax is fluent and logical, there are a million tools and clients…For the most part it’s also super stable and fast but when it comes to what we’re doing at Treblle it starts to show its weaknesses.
The main problem we had was concurrency. The database had to handle a lot of operations per second without burning out We'd have days where we'd process 5M API requests in a single day, or days where we would need to process 200K requests in 5 minutes and similar. Most of our queries are actually pure INSERT or SELECT. We actually try to actively avoid using complicated queries and joins. Besides our concurrency problems we also had issues with running queries like COUNT, SUM, AVG on tables with 10-20M rows. It would timeout, take 30 seconds to sort, run out of memory and everything in between. It all got to a point where we couldn’t analyze our own data, understand our product nor run a top notch service. At least not for the amount of money we wanted to pay. At that time we were paying about 500-600 USD just for our RDS instance. The easiest thing we could have done was just keep adding firepower to it and doubling our AWS bill week after week. A totally valid solution - if you have the money to burn 🤑. We wanted to have something more permanent, cost effective and optimized. Basically we wanted to have the best of both worlds.
At the same time this was happening I’ve read many amazing blog posts and tweets about this database called SingleStore. I first dismissed it because I thought I'd have to change a lot of the database to make it work - but I was wrong. I'm actually glad I was wrong. The way I started explaining SingleStore to my developer friends is: imagine if MYSQL and Redis had a baby it would be called SingleStore. In its essence it’s a special kind of database that has MYSQL syntax, the performance of Redis as well as unparalleled scale. It’s been designed and built to power data intensive applications, real-time platforms, analytics and similar. Just to give you some context about the performance differences: your run of the mill MYSQL could stretch to about 1M TPS whereas SingleStore can do 10M TPS without breaking a sweat. Naturally this piqued my interest. My main concern was: how different it is in terms of MYSQL and what type of adjustments would I need to make?
SingleStore gotchas
After a few days of my own research I jumped on call with Domenic and Sarung from SingleStore. Two amazing individuals, who literally explained everything I wanted to know and set up the next few calls with two of their DB engineers Aditya and Remi. I’ve probably had 10-20 calls with these guys and asked a million different questions: how to do this, how to do that, what happens here, there…They walked me through the entire process, explained the differences, helped me rewrite some queries, helped me create my migration pipeline. Everything. Hats off to the entire SignleStore team for such a hands-on experience. It's something I'll never forget and I'll blatantly try to copy at Treblle.
The first thing you should understand when we talk about SingleStore is that you’ll lose some features of MYSQL that you are traditionally used to. The two ones that I’d like to point out are: foreign keys and the ability to ALTER columns if you’re using a COLUMNSTORE. Now if you can’t make it without these two you should look elsewhere. At first I was also a bit taken back but you can easily fix the missing foreign keys on the application level. The ALTER issue can also be solved by making a new column with the updated data type and copying over the data from one column to another. The good thing about this is that SingleStore can copy data between columns in milliseconds.
Now that we know what’s possible and what no let’s move on to some of the core concepts. Every table you make will have a SHARD KEY. These keys determine in which partition a given row in the table is stored. SingleStore databases are partitioned into multiple different database partitions. That enables it to perform much faster INSERT as well as SELECT query. For an example, if you’re doing a SELECT on 10M rows, SingleStore doesn’t need to run the command on all 10M rows, it can go to a smaller partition that has only 500K and run it there. Truly amazing! Using shard keys couldn’t be simpler. If you create a table with a primary key on it, SingleStore will set that primary key as the SHARD KEY. Alternatively you can define one on your own just by doing something like this:
CREATE TABLE `collections` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`description` text COLLATE utf8mb4_unicode_ci,
`num_views` bigint unsigned NOT NULL DEFAULT '0',
`user_id` bigint unsigned NOT NULL,
`uuid` char(36) COLLATE utf8mb4_unicode_ci NOT NULL,
`created_at` timestamp NULL DEFAULT NULL,
`updated_at` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
SHARD KEY `__SHARDKEY` (`id`),
KEY `collections_user_id_index` (`user_id`) USING HASH,
KEY `collections_uuid_index` (`uuid`) USING HASH
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;In the above example you can also see that I added an INDEX to the uuid field to speed up any lookups we might have. You can see that INDEX has a few additional keywords in the form of USING HASH. This is the go to index type in SingleStore. If you don’t know what type of index to use, go with the hash one 😂 In all seriousness you can find the list of index types right here and you can understand which one is used in which case.
The final thing I’d like to highlight in terms of database structure is the notion of CLUSTERED COLUMNSTORE keys. If you have a column which is used a lot in sorting queries you should add a clustered columnstore index on it and you’ll essentially give it an additional boost in performance.
Migration process
My absolute number one fear of switching databases was the migration process. Given that we’re an real-time API platform the amount of downtime we can have is pretty limited. I’ve migrated a few bigger databases in my life and let me tell you a secret: something always goes wrong. It’s a given. To minimize mistakes I’d start writing the migration process days earlier. It would be sort of a checklist of what to do and what not to forget. The biggest problem in our case was the volume of data. Tens of millions of rows and gigabytes of data. The only way to move it from RDS to SingleStore was by using the AWS Export to S3 option. The way that process works is: you backup your database in RDS, after that you press Export to S3 on the backup and you wait. And wait…and wait. We had to wait around 30minutes for the export to finish. That’s a lot. Like really a lot. I was thinking we would do the entire migration process in 10 minutes but that was no longer the option.
I had to adjust the plan and decided to manually migrate smaller tables. When i say smaller I mean less than 500K of rows in them 😅. These exports were much faster and would be manageable in terms of data discrepancies. The plan was to start moving on a Sunday while most of the world was sleeping. Our newly created ETL microservice was locked an loaded. We just had to adjust our database structure to fit SingleStore. Because we use Laravel migrations, which at the time didn't have support for SingleStore specific keys, I ran all of them them locally and then adjusted the structure in SQL directly. To show you in practice what the differences are you can take a look at this simple comparison I drew:
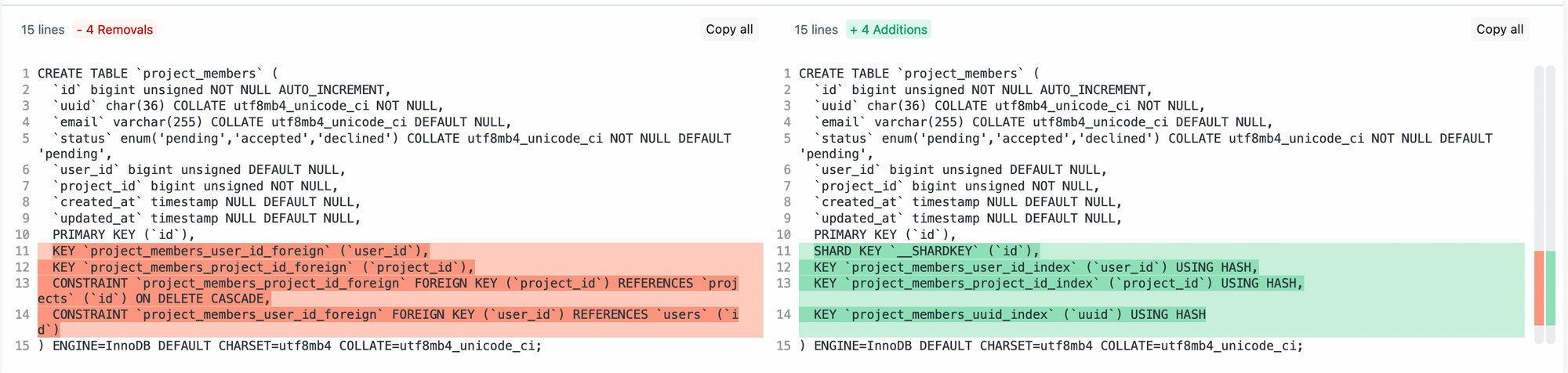
Literary a month later a SingleStore Laravel package comes out with native support for the special syntax. You can find it right here and it'll save you all the trouble I went through of running migrations locally then adjusting the table structure. With this Laravel package you can literally write all the SingleStore specific keys/indexes directly in your migration files.
Now that we have our structure in place it’s time to move the data from RDS to SingleStore. The way you do that, in SingleStore world, is by building a pipeline. The make this easier for you here is a pipeline, from start to finish, for one of our tables:
/* CREATE project_members PIPELINE */
CREATE OR REPLACE AGGREGATOR PIPELINE `project_members`
AS LOAD DATA S3 '_BUCKET_NAME_/_EXPORT_NAME_/_DATABASE_NAME_/_DATABASE_NAME_.project_members'
CONFIG '{"region": "us-east-1"}'
CREDENTIALS '{"aws_access_key_id": "_YOUR_KEY_", "aws_secret_access_key": "_YOUR_SECRET_"}'
SKIP DUPLICATE KEY ERRORS
INTO TABLE project_members
FORMAT Parquet
(
`id` <- `id`,
`uuid` <- `uuid`,
`email` <- `email`,
`status` <- `status`,
`user_id` <- `user_id`,
`project_id` <- `project_id`,
@var <- `created_at`,
@var2 <- `updated_at`
)
SET created_at = timestampadd(MICROSECOND, @var, from_unixtime(0)),
updated_at = timestampadd(MICROSECOND, @var2, from_unixtime(0));
/* START project_members PIPELINE */
START PIPELINE project_members;
/* SYNC project_members AUTO_INCRMENT */
AGGREGATOR SYNC AUTO_INCREMENT ON production.project_members;
/* STOP project_members PIPELINE */
STOP PIPELINE project_members;As you can see, the first thing we do is create a new pipeline for each of the tables we are migrating. Since we’re importing from Parquet we need to map the fields on the export with the fields on the import. As part of the pipeline creation process we also had to re-format the timestamps because of the way Parquet handles UNIX timestamps. Now, you can run this all at once but I'd suggest doing it step by step. First create the pipeline, start it whenever you're ready to start importing. Sync the increments and finally stop the pipeline. To see how you import is doing your can run a command like this:
SELECT COUNT(pipeline_name) FROM pipelines_files WHERE file_state != 'Loaded'Running that command will tell you exactly how much data is imported and what still needs to be imported. A real life safer while running the pipelines. The last peace of the puzzle is this command: AGGREGATOR SYNC AUTO_INCREMENT. The first time I imported 10M rows SingleStore didn’t update the auto increments on the tables 😰 That ment that any new rows would start getting IDs that already exist in the database and that's a big no no. To avoid such a thing from happening you write the query and manually trigger the sync process.
The whole process lasted about 45 mins because I waited for AWS to finish exporting the database to S3. SingleStore literally imported all the rows in less than 5 minutes 🤯
The end result
Our goal was simple: speed up the time it takes us to process a single API request. We did 3 things: re-wrote our code base to be more optimized, moved away from a monolithic architecture, replaced RDS with SingleStore. When we started my goal was to improve by a 100ms. I thought that would be amazing. When I first saw the new number I initially thought it was a mistake 🤣. We use Vapor to keep track of many different perfomrance metrics so I though maybe they have a bug or maybe the numbers didn't update correctly. I left it running for a week to see what happens, but it was still the same number.
As you remember, before all of this, it used to take us about 550ms to process a single API request. After everything we did here it now takes us 94ms to do the same job.
As you remember, before all of this, it used to take us about 550ms to process a single API request. After everything we did, as I described, it now takes us 94ms to do the same job 🔥🤯😍😲
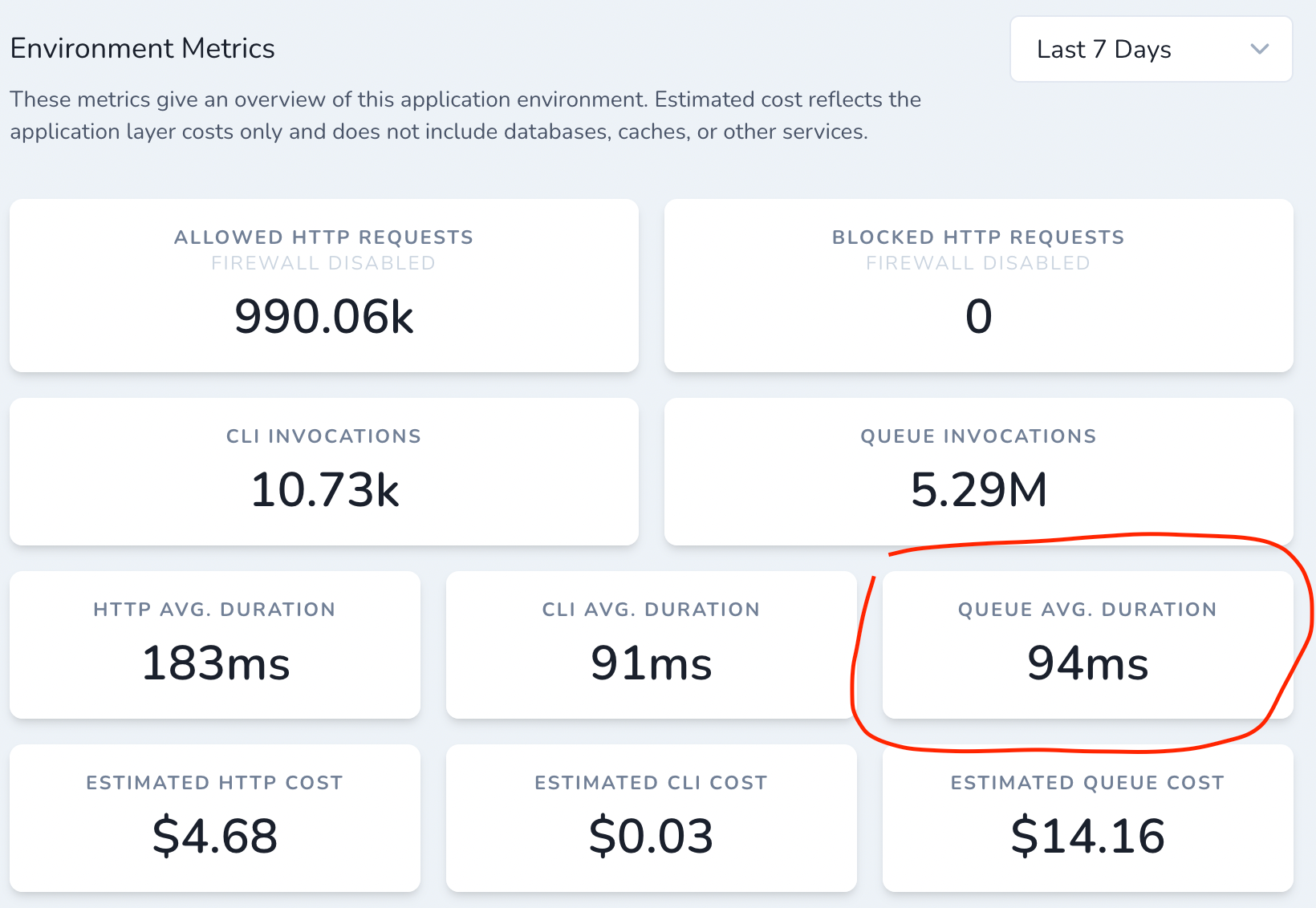
Yes. It's not a mistake. We've processed more than 80M API calls since then. We’ve been able to shave off 450ms in processing time. Given that we run everything inside AWS Lambda this means that we’ve also slashed our AWS bill by almost 5x. Given that we get charged by the number of MS we spend executing code this is amazing for us.
You're probably wondering what had the biggest impact on the performance. My answer to you would be SingleStore. I'd say it accounts for around 50% of the overall improvement. Yes, we did optimize the s**t out of our code. I wrote some of the better code I ever did in my life. Yes it allowed us to improve and win a few battles but database is where wars are won. We can now sort tables with 20M rows in miliseconds instead of 10+ seconds. There are no slowdowns, lags, overfloads..nothing. It all just works. Also, we're using the smallest possible instance on SingleStore, S0, which we pay less than 500USD for. It has never gone more than 25% of memory usage nor cache usage. We will most likely upgrade to an S1 because it comes with more firepower and some other benefits. For now I'm super happy.
Pretty good I think, especially for someone who tries to avoid scaling for a living.
Again, as I write the last words of this article we are already working on the next iteration of our scale. Remember: as soon as you stop you lose.
Before we wrap up a few thank yous are in order. Thank you to our back-end developer Akhil for helping me do all of this, Tea for relentlessly testing and helping me on the day of the transfer. The SingleStore guys Domenic, Sarung, Aditya and Remi for guiding me through this.
PS. I recently recorded an complete, in-depth tech demo of what Treblle does, how it works and why it's awesome. If you have a couple of minutes take a peek:




