

In a previous blog I've talked about structuring Minimal API.
One of the differences I mentioned was “better fit for vertical slice architecture”.
So today I want to explain to you a few things:
- What is vertical slice architecture?
- What makes them different from traditional approach
- How to implement this architecture with Minimal API?
But before we dive into the “new way” of creating APIs, let's take a brief look at the traditional approach.
Layered “traditional” way
The traditional layered approach in software architecture refers to a design method that organizes a system's components or modules into distinct layers, each responsible for specific functionalities.
The most notable architectures utilizing this approach are:
- N-Tier architecture
- Clean architecture
- Onion architecture
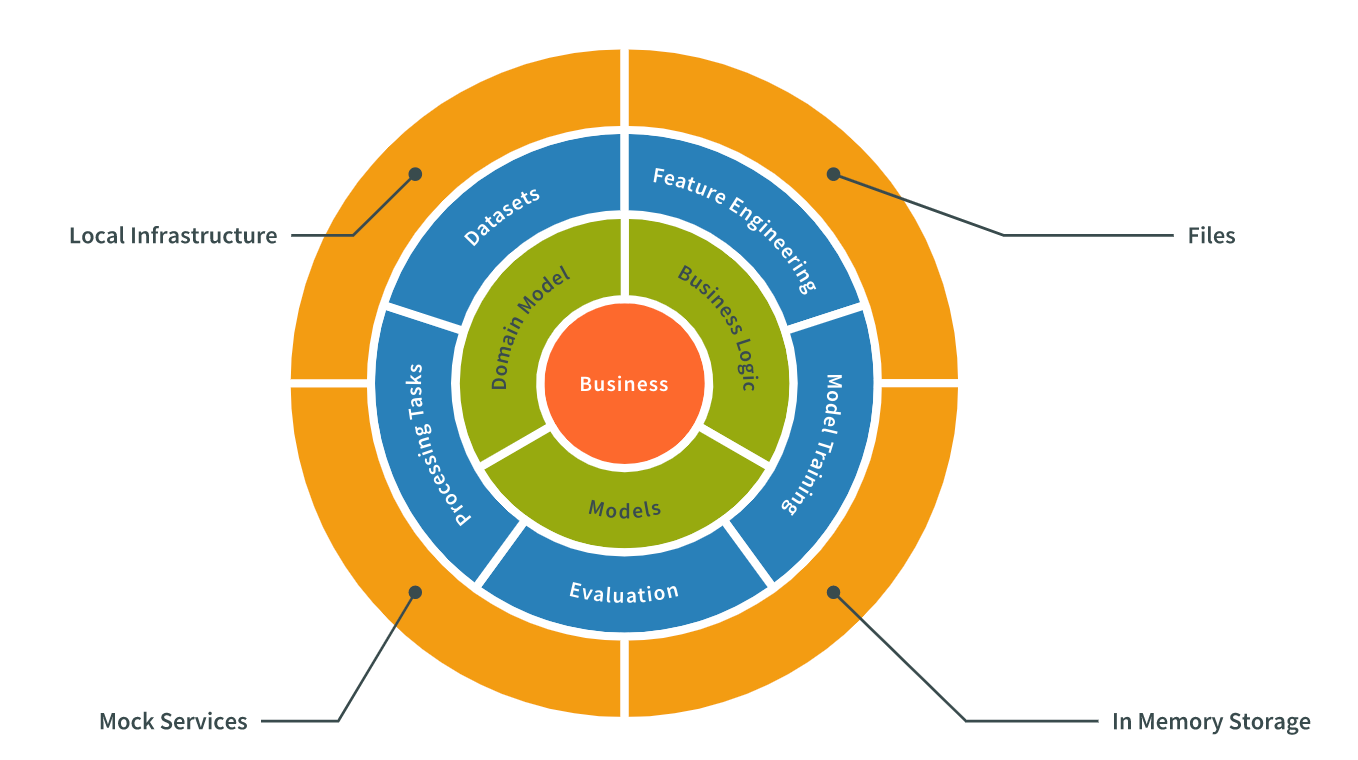
Here, each layer communicates with the adjacent layers following specific guidelines.
Often adhering to principles like separation of concerns and single responsibility, where each layer focuses on its designated tasks without tightly coupling with other layers.
But, this approach has a few challenges.
Challenges of layered architecture
As with everything in the world of software development, benefits are often followed by challenges.
Layered architecture introduces:
- Tight coupling between layers: Changes in one layer might affect others because tight coupling can hinder flexibility and make the system more fragile.
- Dependency management: Changes in one layer might necessitate modifications in dependent layers.
- Choosing the right abstraction level: Over- or under-segmentation of layers can lead to architectural issues.
Now, aware of these challenges, consider how you structure a feature.
Do you progress from “top to bottom,” intersecting the layers?
If so, congratulations, you are now thinking in slices.
What is vertical slice architecture?
Vertical Slice Architecture (VSA) is a software development approach that organizes applications into distinct functional slices.
The fundamental concept behind this architecture involves grouping code based on business functionalities and consolidating related code.
This approach yields several benefits:
- Reduced coupling: Coupling between features is minimized. Entire feature implementations reside within one slice, enhancing maintainability.
- Streamlined testing: Testing becomes more straightforward by focusing on individual slices, ensuring each feature functions as intended.
- Flexibility and adaptability: VSA provides flexibility for scaling, deployment, and future modifications without impacting the entire system.
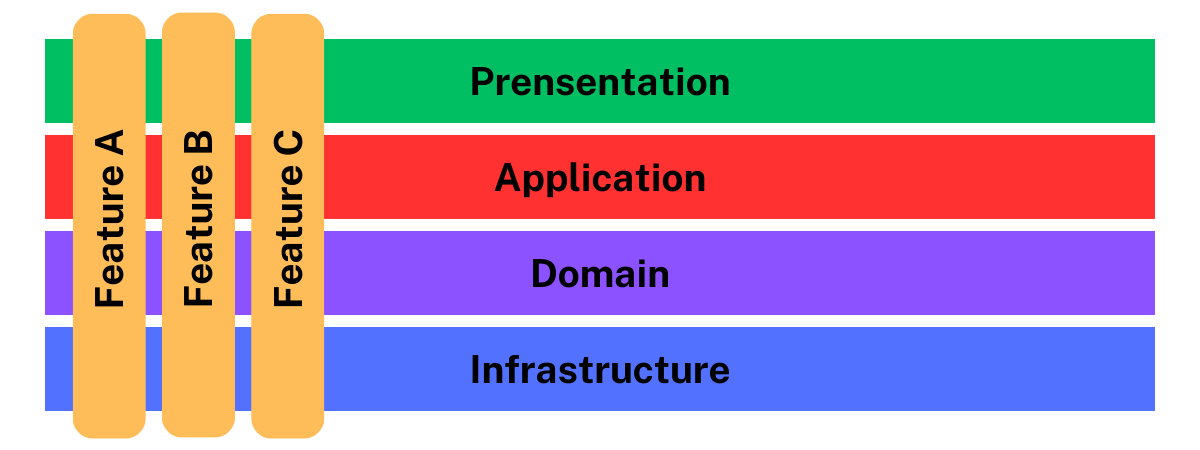
Before we dive into the implementation part, we need to:
- Point out difference between this two architectures
- Explain what is slice
Vertical slice vs layered architecture
| Aspect | Vertical slice architecture | Layer architecture |
|---|---|---|
| Scope | Focuses on end-to-end feature development for a single vertical or user story. | Divides the application into horizontal layers (e.g., presentation, business logic, data access) |
| Organization | Organized around features/modules. | Organized around functional layers |
| Dependency management | Reduces inter-module dependencies by encapsulating complete feature sets. | Tends to have interdependencies between layers. |
| Flexibility | Easier to modify or replace specific features/modules. | Changing one layer may impact other layers. |
| Testing | Encourages comprehensive testing of specific features/modules. | Testing often involves mocking layers for isolated tests. |
| Initial setup | Often quicker to set up as it involves a smaller initial scope by focusing on a specific feature. | May require more upfront planning and architecture design to establish the structure of various layers. |
| Complexity | Helps in managing complexity by focusing on cohesive feature development, potentially reducing the complexity within each vertical slice. | May lead to increased complexity within individual layers but promotes separation of concerns. |
| Maintenance | Easier to maintain individual features/modules. | Maintenance can be complex due to interconnected layers. |
As you can see from the table, both approaches have their merits, and the choice ultimately depends on achieving the right balance between maintainability, flexibility, and scalability.
What is a slice?
A "slice" denotes a self-contained development unit within an application, encompassing all necessary layers to implement a particular feature.
Every slice operates independently and strives to deliver a fully functional segment of the application capable of functioning autonomously.
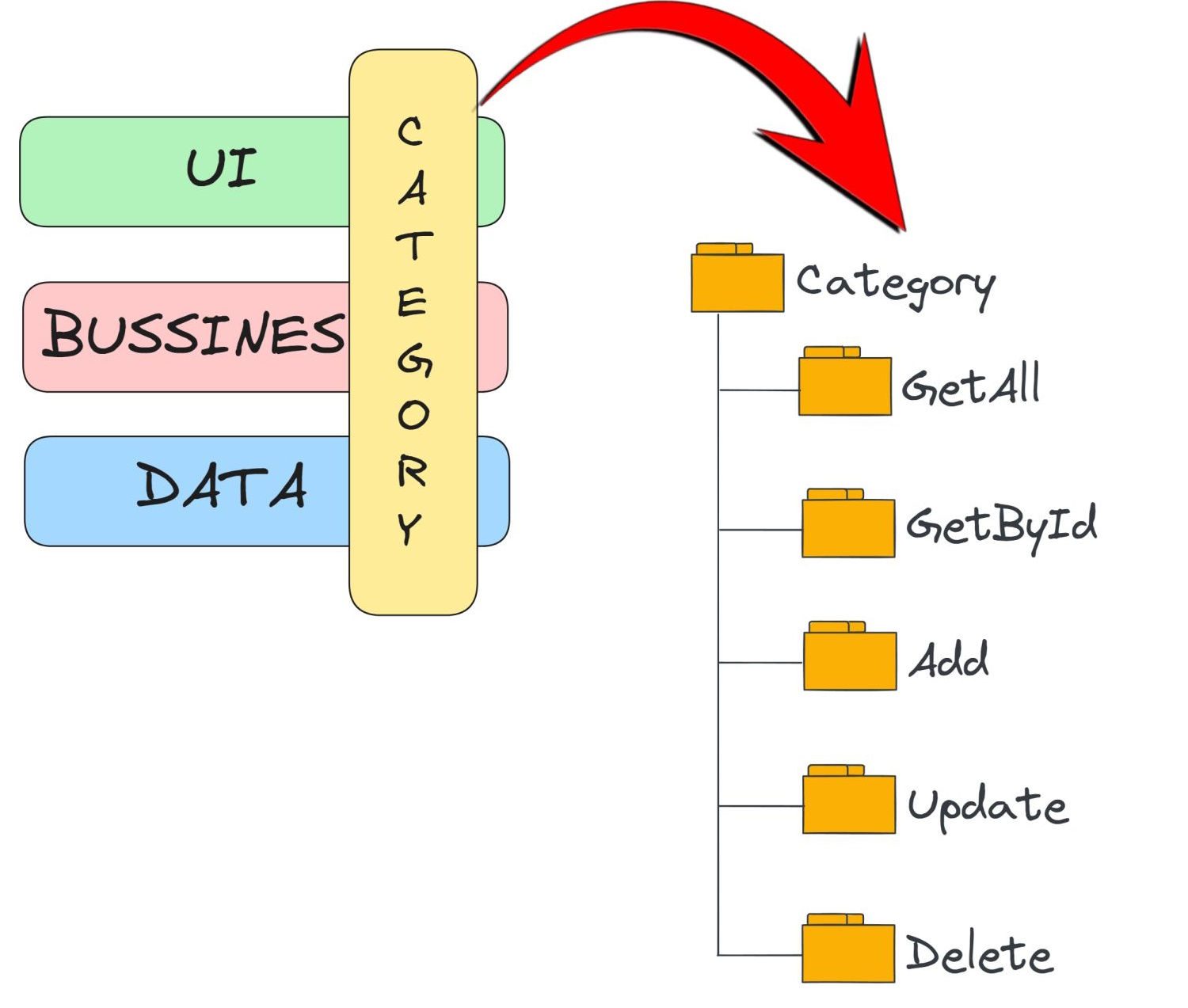
And now…the implementation part!
Implementing vertical slice architecture with Minimal API
For the sake of simplicity, we are going to rely on data from previous post.
This is the project structure:
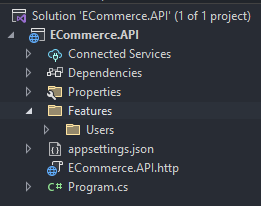
I predominantly employ the Features folder approach for code organization.
This method mandates structuring slices within a single folder as extensively as feasible.
Features can be defined in two ways:
- Shallow organization: Code is arranged based on technical concerns.
- Deep organization: Code is structured according to the action it performs.
Moreover, this approach necessitates the implementation of the CQRS pattern since each slice is divided into sub-slices, or endpoints.
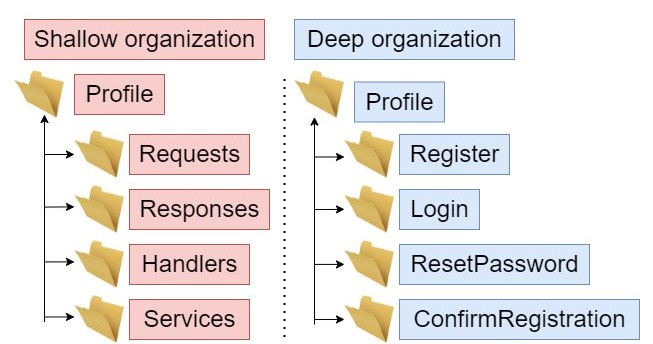
Personally, I favor deep organization due to its advantages in maintainability and ease of navigation.
However, feel free to utilize the approach that best suits your preferences.
Now that we've finalized the project structure, let's direct our attention to defining the contents of each individual slice.
Slice setup
Each slice functions as a separate, independent unit, akin to a thread. In other words, a slice can be agnostic to the underlying libraries it employs.

One slice can use EF Core, second raw SQL, and third can use stored procedure. Use whatever fits your needs to achieve the desired result.
All our slices will follow the REPR pattern.
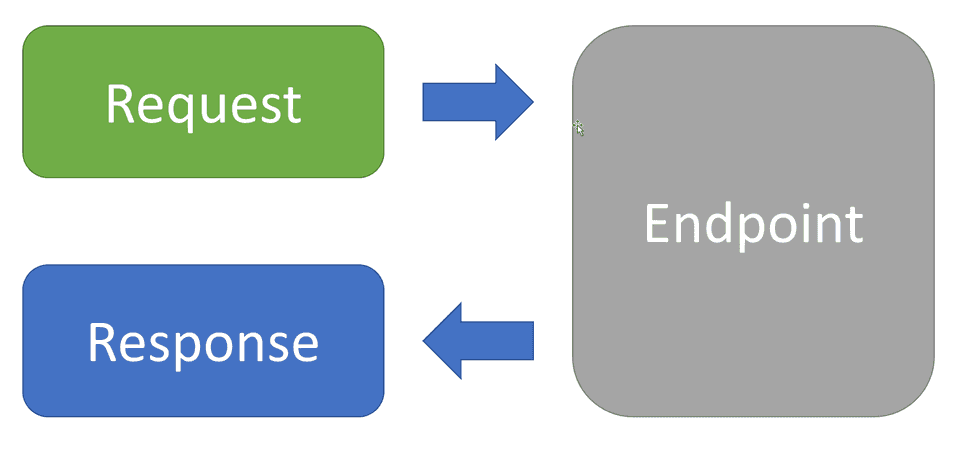
It delineates web API endpoints with three primary components:
- Request: Contracts outlining the expected data for the endpoint.
- Endpoint: Business logic executed upon receiving the request.
- Response: Contracts conveying the output produced by the handler.
Why REPR?
The solution is simple.
By consolidating the request, endpoint, and response within a slice, you minimize the time spent navigating through layers, thereby enhancing the maintainability and ease of working with endpoints.
Request and response contracts
Simply put, these two serve as Data Transfer Objects (DTOs), exclusively designed for data transfer purposes. Achieving immutability would be highly advantageous.
Fortunately, records align perfectly with this requirement.
We'll be implementing two endpoints:
- Get Users: Queries all active users within the system.
- Add User: Adds a new user to the system.
The folder structures will resemble the following:
For achieving full immutability, we are going to use positional records:
- Get users:
This endpoint is dedicated to retrieving all users for read-only purposes. Consequently, only a response object is required in this context.
public class Contracts
{
public record Response(string FirstName,
string LastName,
DateOnly BirthDate,
bool isActive);
}
- Add user:
The request will bear resemblance to the response object from GetUsers, with added properties.
Meanwhile, for the response, we'll return the newly created Id.
public class Contracts
{
public record Response(string FirstName,
string LastName,
DateOnly BirthDate,
bool isActive,
string Address,
string PhoneNumber);
public record Request(int Id);
}
In both scenarios, we utilize a root class named Contracts.
While employing positional records, I typically opt to consolidate them within the same file to expedite navigation and ensure easier maintainability.
However, the choice of organizing records per file is also feasible.
Regarding the contract, our task is complete.
Let's proceed to the endpoint.
Endpoint
For the endpoint handler, we'll employ a class segregated into two parts:
- Handler: Housing the business logic.
- AddEndpoint: A Minimal API endpoint responsible for consuming the handler method.
public static class Endpoint
{
private static List<User> GetUsers() =>
Collection.Users
.Where(user => user.IsActive)
.ToList();
public static void AddEndpoint(this IEndpointRouteBuilder app)
{
app.MapGet("api/v1/users", () =>
{
var activeUsers = GetActiveUsers();
return Results.Ok(activeUsers);
});
}
}
public static class Endpoint
{
private static Response AddUser(Request request)
{
Collections.Users.Add(request);
return new Response(request.Id);
}
public static void AddEndpoint(this IEndpointRouteBuilder app)
{
app.MapPost("api/v1/users", (Request request) =>
{
var response = AddUser(request);
return Results.Ok(response);
});
}
}
I employ a practice known as mouse wheel-driven development, emphasizing the consolidation of all related data within a single file.
However, this approach might conflict with the Single Responsibility Principle (SRP), posing a tradeoff between expedited and centralized development and the adherence to SRP for better code organization.
It the end, add endpoint to the pipeline:
var app = builder.Build();
GetUsers.Endpoint.AddEndpoint(app);
AddUser.Endpoint.AddEndpoint(app);
Possible problem and solution
While this approach seems suitable for managing a small number of features, scaling it to handle 50+ slices could pose challenges.
In such scenarios, I recommend considering specialized libraries:
- Fast Endpoints: Described as a developer-friendly alternative to Minimal APIs & MVC
- Api.Endpoints: Designed to support API Endpoints in ASP.NET Core web applications.
Scaling to a larger number of slices might lead to various code smells, such as:
- Shared code:
- Smell: Repeated code or logic scattered across multiple slices, indicating a lack of shared components or libraries.
- Solution: Identify common functionalities and refactor them into shared components to prevent duplication and encourage reusability.
- Cross-Cutting Concerns:
- Smell: Duplication of implementations like logging, error handling, or authorization across slices.
- Solution: Extract and centralize cross-cutting concerns into shared modules to ensure consistency and minimize redundancy.
- Poorly Defined Slice Boundaries:
- Smell: Ambiguity in delineating slice boundaries, leading to overlaps or gaps in functionality.
- Solution: Clearly articulate the scope and boundaries of each slice, ensuring they encapsulate all necessary components for delivering specific features. Continuously refine these boundaries through discussions and reviews to maintain clarity and coherence.
Conclusion
The integration of Minimal API alongside vertical slice architecture represents a transformative paradigm in software development, providing an efficient means to design and deploy APIs.
Emphasizing simplicity, clarity, and modularity, this architectural approach streamlines the development process while elevating the maintainability and scalability of applications.
In conclusion, here are two crucial considerations, akin to "gold nuggets," to ponder before implementation:
- Single Responsibility Principle: Embed all related components (controllers, services, repositories, etc.) pertaining to a feature within a slice. This practice maintains clear and focused responsibilities within the architecture.
- Focused Endpoints: Refrain from overloading endpoints with excessive functionalities or intermixing concerns from disparate slices. Maintain endpoint focus aligned with specific slice responsibilities to enhance code clarity and maintainability.




