

Summary:
• Slack suffered a major outage on February 26, 2025, disrupting communication for thousands of users.
• The root cause was traced to failures in database shards, which led to API breakdowns.
• The outage lasted approximately 10 hours, impacting multiple Slack features.
• API intelligence could have detected early warning signs like error spikes and traffic anomalies.
On February 26, 2025, cloud-based messaging platform Slack experienced a major outage, disrupting communication for thousands of users and highlighting the growing need for powerful API Intelligence.
In this article, we explore what went wrong during the incident, why API intelligence is unavoidable for preventing such disruptions, and how proactive observability can safeguard digital services.
What Went Wrong
The Slack outage began early in the day around 10:30 a.m. EST, when users started reporting problems connecting to the platform. At its peak, this Slack outage generated 3,099 reports on Downdetector.
Reports mentioned trouble with logging in, messaging, apps/integrations/APIs and workflows. Investigations revealed that several API endpoints were affected, causing degradation in performance across multiple features.

As Slack officially reported, the root of the problem was traced to issues with database shards—a critical component responsible for handling and distributing the load of data requests.
As these shards encountered unexpected errors, the APIs that connect the front-end interface to the back-end infrastructure failed, leading to widespread service disruption.
According to Slack's official status page, it took approximately 10 hours for the issue to be investigated and fully restored.

The Importance of API Intelligence
This incident highlights the growing need for powerful API intelligence. At its core, API intelligence involves observability, analyzing, and managing the data exchanged between systems.
It provides real-time visibility into the performance and health of APIs, enabling organizations to detect anomalies and address potential issues before they escalate into full-blown outages, like in the example with Slack.
Consider the early warning signs that a powerful API Intelligence system might capture: a sudden increase in error rates, unexpected latency spikes, or unusual traffic patterns.
These indicators can serve as early alerts that something is wrong within the digital ecosystem. By catching these issues on time, companies can engage in proactive troubleshooting rather than reactive firefighting.
General API intelligence strategies often involve several key components:
- Real-Time Observability: Continuous observation of API traffic, response times, and error rates helps in identifying unusual patterns that may indicate underlying issues.
- Complete Logging: Detailed logs capturing every request and response provide the necessary data to trace the source of a problem. This can be invaluable when diagnosing complex issues, such as those related to database shards.
- Automated Alerts: Systems can be configured to trigger alerts when specific thresholds are breached, ensuring that the right teams are notified immediately when anomalies are detected.
- Performance Analytics: By analyzing usage patterns and response metrics, organizations can better understand the normal operating conditions of their APIs and quickly spot deviations.
Where API Intelligence Comes Into Play
In the context of these challenges, platforms like Treblle have emerged as mandatory tools for enhancing API intelligence. Treblle provides detailed insights into API performance by observing over 40 data points for each request.
This level of granularity means that anomalies—such as those that might have caused the Slack outage—can be identified and addressed in near real-time.
Consider the early warning signs that an advanced API intelligence platform could detect:
- Spike in error rates – A sudden increase in failed API requests.
- Unexpected latency spikes – Slow response times that indicate a backend issue.
- Unusual traffic patterns – Surges or drops in API calls that may signal a problem. Detecting these anomalies early is key to preventing API abuse, which can lead to security risks and service disruptions.
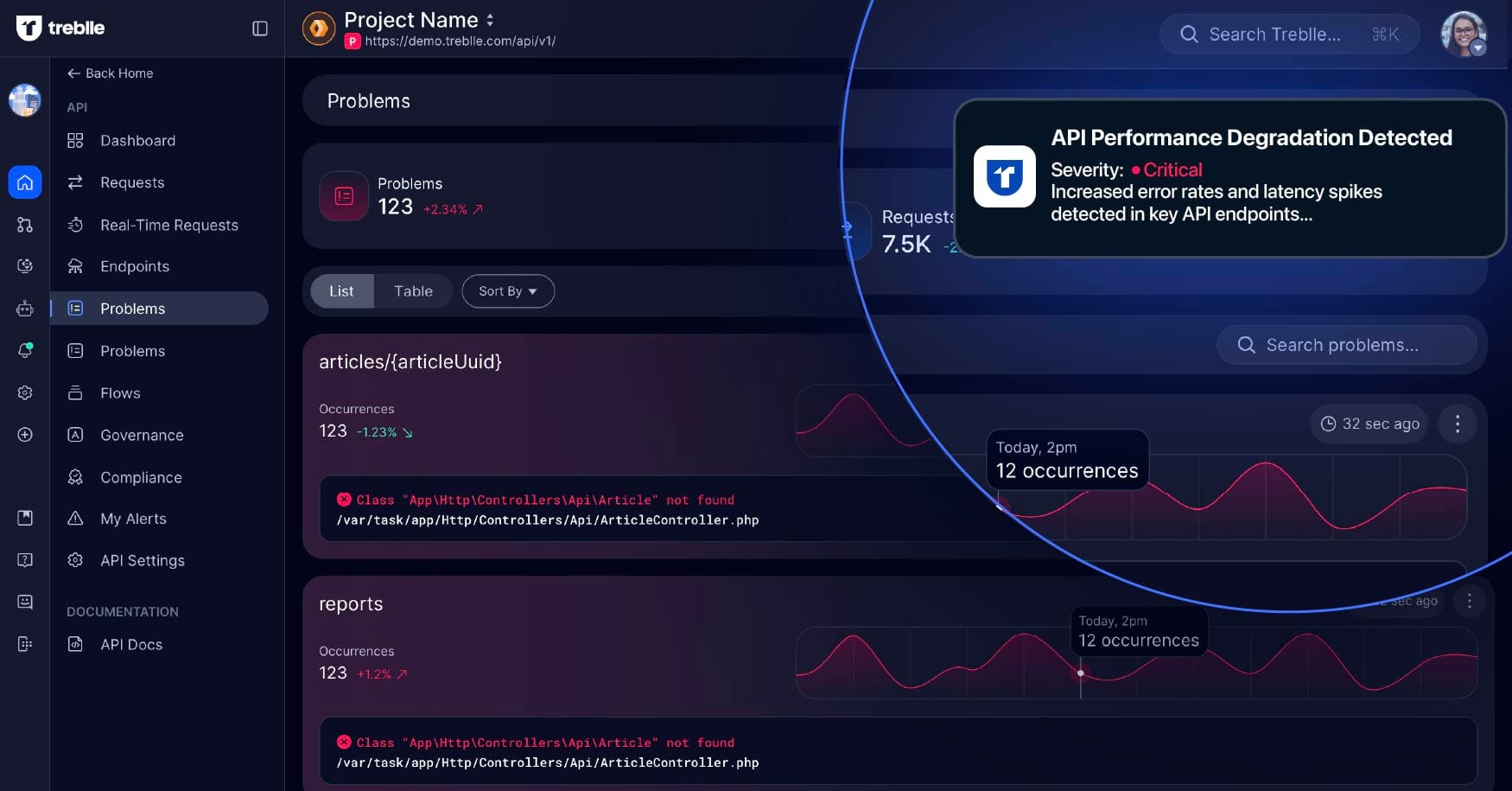
Treblle’s intuitive logging capabilities enable teams to trace issues from the moment they occur, allowing for faster resolution. By automating the generation of up-to-date API documentation and providing advanced analytics, Treblle helps organizations not only react to issues but also plan and optimize for future performance improvements.
What’s next?
The Slack outage is a wake-up call for all companies relying on API-driven architectures. It underscores the need for API intelligence solutions that offer continuous observability and proactive error detection.
By leveraging such tools, organizations can ensure higher reliability, improve user satisfaction, and ultimately maintain the trust and reputation that is so critical in today’s digital-first world.
While no system is immune to unexpected issues, investing in powerful API Intelligence can make the difference between a minor hiccup and a major service disruption. As we continue to build increasingly interconnected digital ecosystems, the role of API Intelligence will only grow more essential.




