
I’m a big fan of Batman, always have been and always will be. Dark Knight is one of my all time favorite movies. Have I imagined being Bruce Wayne more times that I should have - why yes I have. What’s stopping me, you ask? Well, theoretically I could get lean, learn MMA (or Jiu-Jitsu like Zuck) and stop being, ever so slightly, afraid of heights. But, but, but…I am missing about $100B in my bank account that would allow me to have all the cool toys, cars, caves as well as a butler. So being the grown up that I am (😉) I decided to put that dream aside and focus on the next best thing: building my own personal Alfred. Except my Alfred helps fight the injustices in the API world and not bad the guys of Gotham City.
Two things before we continue:
- First - just realized that Zuck could actually be The Batman 👀😱. He’s worth $103B, is fit and, like I mentioned, knows Jiu-Jitsu… 🤔
- Second - we need to queue some tunes before we continue. Without Me by Eminem makes perfect sense because it matches the theme and we’ll pretend this is my small comeback to writing 🙂
The year of the AI
The Chinese Zodiac says that 2023. is the year of the Rabbit. Numerology says it’s the year of Spiritual Reflection. VCs have it pinned down as the year of the AI 🙃. Basically, everyone is all-in on AI.
Don’t get me wrong I have nothing against AI. Personally, I think it’s one of those evolutionary things. It’s inevitable, it was bound to happen and I’m really excited to see where it goes next. But the hype around it is something I’ve never seen before. The crypto bubble seems like a little baby compared to this. Everyone is building AI tools, assistants or baking it into their product in one or the other way.
On the surface all of those seem groundbreaking, 10x time saving, revolutionary and will eventually leave us without a job type of products. Well, at least that’s how they’re marketed. The reality, however, is a bit different. In most cases, these tools are just a handful of API calls to a few core services like OpenAI, Bard, AWS, Azure and others. Yes, there’s a lot of innovation happening on an ML/LLM level and there are folks who are doing some really interesting stuff but AI powered Kombucha isn’t one of them.
The good thing, for us at Treblle, is that all of this AI action equals more API calls. That, of course, is good for business 🤑. What makes these AI API calls special is that you need to actually see the inputs and outputs in order to understand the outcomes. What do I mean by that? Let’s say you have an API that simply creates a new account for the user. The outcome of that API call can only be one of two:
- 0 => it didn’t work and the user account wasn’t created
- 1 => it did work and the user account was created.
With these AI tools, however, outcomes can be a lot of things in between. It can be a bad answer, a good one or a horrible one. It really depends on the prompt, the LLM, the training set and a lot of other things…the point is you need observability and understanding in order to figure this out. Coincidentally Treblle is amazing at this 😛.
But being amazing at observability doesn’t mean we’re immune to market trends. Every VC, industry analyst, and random engineering manager I’ve spoken to asked about AI in one way, shape or form. It reminded me of my high school days where if you didn’t listen to Eminen when he released The Eminem Show album in ‘02, simply put - you weren’t cool. I wanted Treblle to be at the cool kids table but at the same time I didn’t want to build yet another useless, bullshit AI product. So I got to thinking.
Hello Alfred;
One of the earliest feature requests that Tea, our Head of native apps, had was the ability to generate code for SwiftUI models based on the API docs. When you’re developing an API it’s quite prone to changes on multiple fronts - from naming conventions, endpoints to the documentation. It’s a lot of manual and boring work to keep these things in sync without going crazy. I told her I’d look into it. And I really did. There were some code generation tools that looked like they could do the job but they all seemed cumbersome and very limited. In classic engineer fashion I whispered to myself: “Vedran, you can do this better yourself - probably in a weekend or less!”. Two years passed and that weekend never came 😅The idea always stuck with me though.
When all the generative AI hype started I wanted to actually see how it renders code. Mostly because I was a bit worried about it replacing me as an engineer 😁. This is one of those primal fears that every engineer has in the back of their mind. If you’re an engineer - you know! Anyhow, my go to test for all these generators is always PHP. It’s probably the most underrated language out there and also the one that I’ve been working with for the past 15 years. So I asked ChatGPT the following: “Show me how to create a POST request using the Laravel HTTP Facade”. Note: See how I wanted to trick it by being super specific with the HTTP Facade. It, however, returned the following:
<?php
use Illuminate\Support\Facades\Http;
$response = Http::post('https://api.example.com/endpoint', [
'param1' => 'value1',
'param2' => 'value2',
]);
if ($response->successful()) {
$responseData = $response->json();
} else {
$statusCode = $response->status();
$errorData = $response->json();
}I wiped the smirking smile off my face and realized that this is quite close to what I would have written myself. After taking a breather and examining my life choices for a moment I realized that we need to somehow put this to work in the context of Treblle.
My next thought was let’s see how much it understands about APIs and OpenAPI Spec. Turns out - a lot. It answered all my questions, no matter how I asked them. I realized that it fully understood OpenAPI Spec and that OpenAI probably trained the model to perfection so it could help them generate connections and integrations faster. (I don’t have any proof of this, it's just a theory. Well, actually, I’m quite convinced at this point because I’ve compared some other LLMs and their understanding of OpenAPI Spec doesn’t come close).
Now, you’re wondering why am I talking about OpenAPI Spec so much? Well, see, APIs are mostly a mess. But one thing that a lot of people have learned not to hate is OpenAPI Spec. It’s the way engineers generally document their APIs. They just do it manually, like cavemen. One of the things that Treblle does is it generates documentation for your API automatically 🤷♂️. You add our SDK, make a request and we figure out what endpoint that is, generate docs for it, build you a developer portal and keep the docs updated as new requests come in. Wham! Bam! Thank You Ma'am.
Given that we already had documentation in OpenAPI Spec format for every API using Treblle I wanted to combine it with the power of OpenAI code generation and natural language understanding. The idea was: you land on our auto-generated developer portal, you can read the docs or you can use the generative, open-ended chat interface to get answers, get code samples, models or tests. The possibilities were endless but the only way it’s actually useful and cool is to understand that exact API documentation.
I knew I had to send the documentation as part of the prompt. Somehow. I first tried this prompt: Give me all the endpoints from this OpenAPI Spec file: https://raw.githubusercontent.com/OAI/OpenAPI-Specification/main/examples/v3.0/petstore.json. It worked like a charm, it read the JSON from that link, understood the documentation and could do anything with it now. But note the link to a file on Github. Turns out that’s a problem. OpenAI won’t read external links except for a select few like Github, Microsoft and a few others. If you’ve ever wondered what $10B gets you - now you know.
After the disappointment with the links I gave up for a few hours until I learned about system messages in the OpenAI API. System messages allow you to basically tell the AI to pretend to be someone or something. For an example “Pretend to be Indiana Jones” or “Pretend to be British and answer only with a British accent” 😆. I realized I could tell it to pretend to be an OpenAPI Spec parser and send the entire OpenAPI Spec as a JSON blog in the first prompt. So when a user asks a question I basically fire of an API call to OpenAI that looks like this:
<?php
use OpenAI\Laravel\Facades\OpenAI;
$response = OpenAI::chat()->create([
'model' => 'gpt-3.5-turbo',
'messages' => [
['role' => 'system', 'content' => 'You are an OpenAPI Spec parser reading this documentation: $this->oas($project->uuid)],
['role' => 'user', 'content' => $request->message],
],
]);
foreach ($response->choices as $choice) {
array_push($messages, $choice->message->content);
}Notice that the first message is actually that pre-prompt with the system role where I send the entire JSON of the OpenAPI Spec for that API. And guess what - it works. With that system message and the raw JSON it can answer any question you ask about that specific API as well as generate any imaginable code with that understanding.
It worked like a charm but it was quite slow. It’s fascinating how we’re super sensitive to the slowness of API calls. I knew the amount of work it was doing in the background, the amount of computational power it was using but waiting 20-30 seconds to get a code example wasn’t sexy. I started testing ways of improving it. The UI was my starting point. I added a bunch of niceties to keep you entertained but that only made it slightly better. I compared Google Bard, OpenAI and a few other specific code generation AIs. I then discovered that Microsoft has its own version of the OpenAI API and for some reason it’s simply faster to respond. I assume it’s because Microsoft is giving it all the power it's got to generate the response and that they don’t have to do a network hop from one server to another like OpenAI has to them. So I ended up using the Microsoft version of OpenAI.
The final piece of resistance was actually implementing streaming. OpenAI allows streaming responses which essentially means that as the AI is returning generated content (letters, code, sentences…) you can get them letter by letter instead of waiting for the entire response. This meant that I could drastically reduce the amount of wait for the user and he would start seeing content appear within 4-5 seconds. Which is amazing. Implementing this in a Laravel running on top of Vapor turned out to be a bit of a hassle. The back-end side of things looks like this:
<?php
namespace App\Http\Controllers\Api;
use App\Http\Controllers\Controller;
use Illuminate\Http\Request;
use OpenAI\Laravel\Facades\OpenAI;
class CopilotController extends Controller
{
public function stream(Request $request)
{
$question = urldecode($request->question);
return response()->stream(function () use ($question, $uuid) {
$stream = OpenAI::chat()->createStreamed([
'model' => 'gpt-3.5-turbo-16k',
'messages' => [
['role' => 'system', 'content' => 'Parse the following OpenAPI Sepcification and use it when answering API related questions: '.$this->oas($uuid)],
['role' => 'user', 'content' => $question],
],
]);
foreach ($stream as $response) {
if (connection_aborted()) {
break;
}
echo "event: update\n";
echo 'data: '.json_encode(['text' => $response->choices[0]->delta->content]);
echo "\n\n";
ob_flush();
flush();
}
echo "event: update\n";
echo 'data: '.json_encode(['text' => '_STOP_STREAMING_']);
echo "\n\n";
ob_flush();
flush();
}, 200, [
'Cache-Control' => 'no-cache',
'Content-Type' => 'text/event-stream',
'X-Accel-Buffering' => 'no',
]);
}
}The front-end part is using a technique called Server-sent Events and looks like this:
// Empty string where we keep the streamed markdown as it comes in
var markdown_string = '';
/*
We need to convert markdown to HTML using: https://github.com/showdownjs/showdown
*/
var converter = new showdown.Converter({
flavor: 'github',
smoothLivePreview: true,
});
// Open a stream to our Laravel OpenAI Controller
const stream = new EventSource('your-url.com/stream?count=' + $('.sender-bot').length + '&question=' + encodeURI(user_message));
// Catch update events returned by our OpenAI Contoller
stream.addEventListener('update', function (event) {
// Stop streaming if we get a specific message text
if (JSON.parse(event.data).text === "_STOP_STREAMING_") {
stream.close();
return;
}
markdown_string = markdown_string + JSON.parse(event.data).text;
$('#your-message-element')
.html(converter.makeHtml(markdown_string));
/*
We are expecting a lot of code and need highlighting using: https://github.com/highlightjs/highlight.js
*/
document.querySelectorAll('.copilot-chat code').forEach(el => {
hljs.highlightElement(el);
});
});That’s all it took to build this whole thing. A couple of APIs, some HTML/CSS/JS and good old PHP. Now let’s see what the thing can actually do for you.
How does Alfred help you?
One of the most beautiful things about generative AI and the way we’ve implemented it to Treblle is that it can help you solve actual API problems. Not only that but you’re not limited to a language or a question or a construct. Given that it literally understands the OpenAPI spec as you and I understand English you can have a conversation with it about your API. Let’s take a look at some API specific prompts.
Basic API understanding
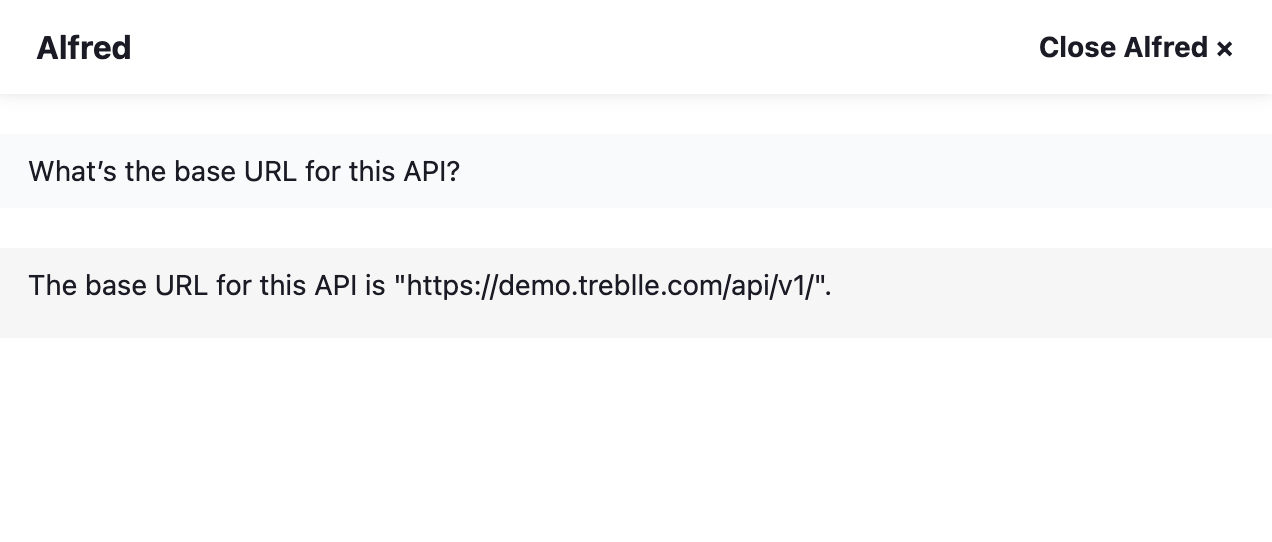
- What’s the base URL for this API? (it returns the exact base URL of your API)
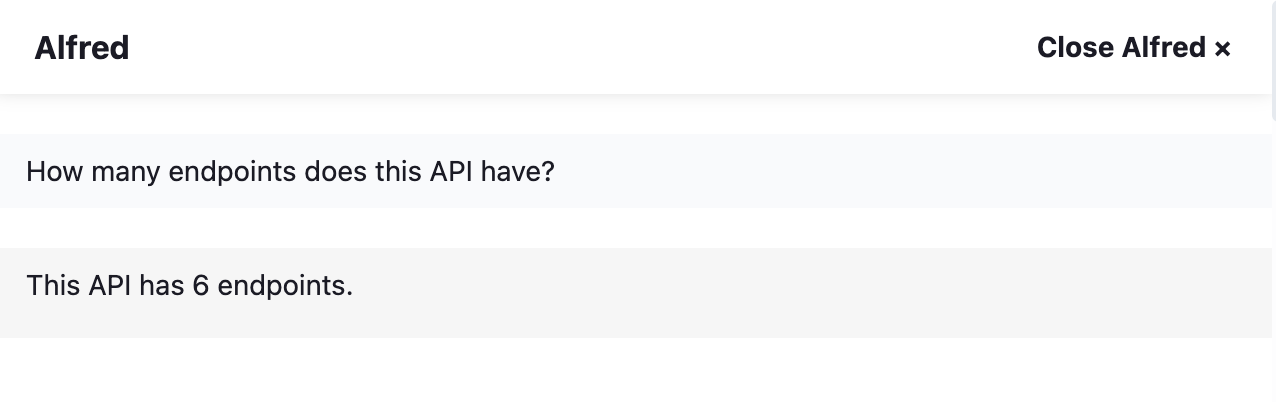
- How many endpoints does this API have? (it counts all the endpoints and tell you exactly how many you have in your API)
- How do I authenticate on this API? (it tells you what type of authentication the API uses and gives you an example on how to use it)

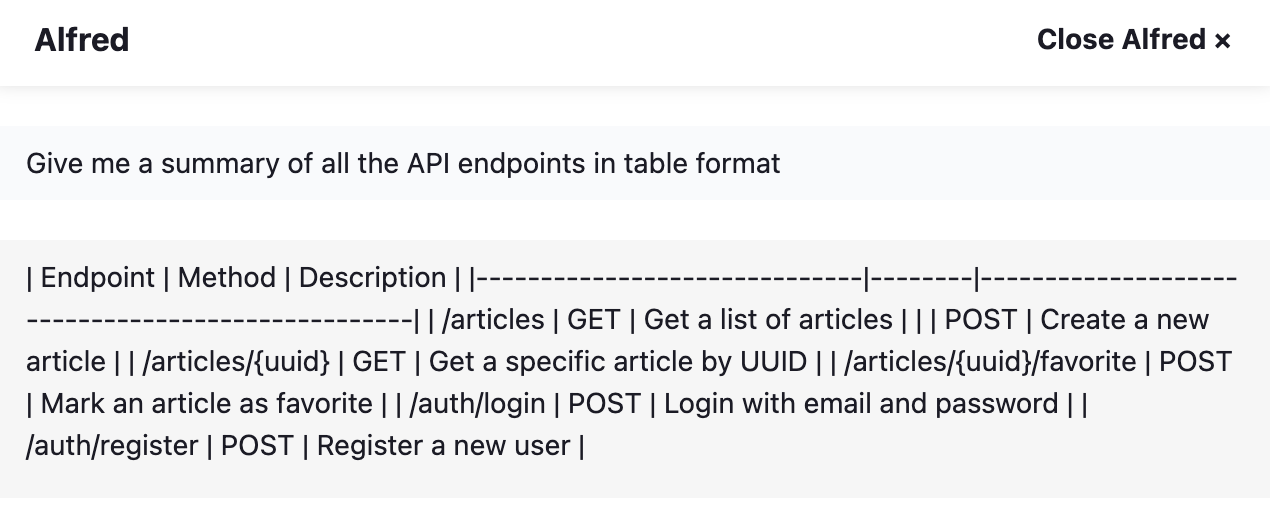
- Give me a summary of all the API endpoints in table format (it shows you a table list with all the endpoints and their methods)
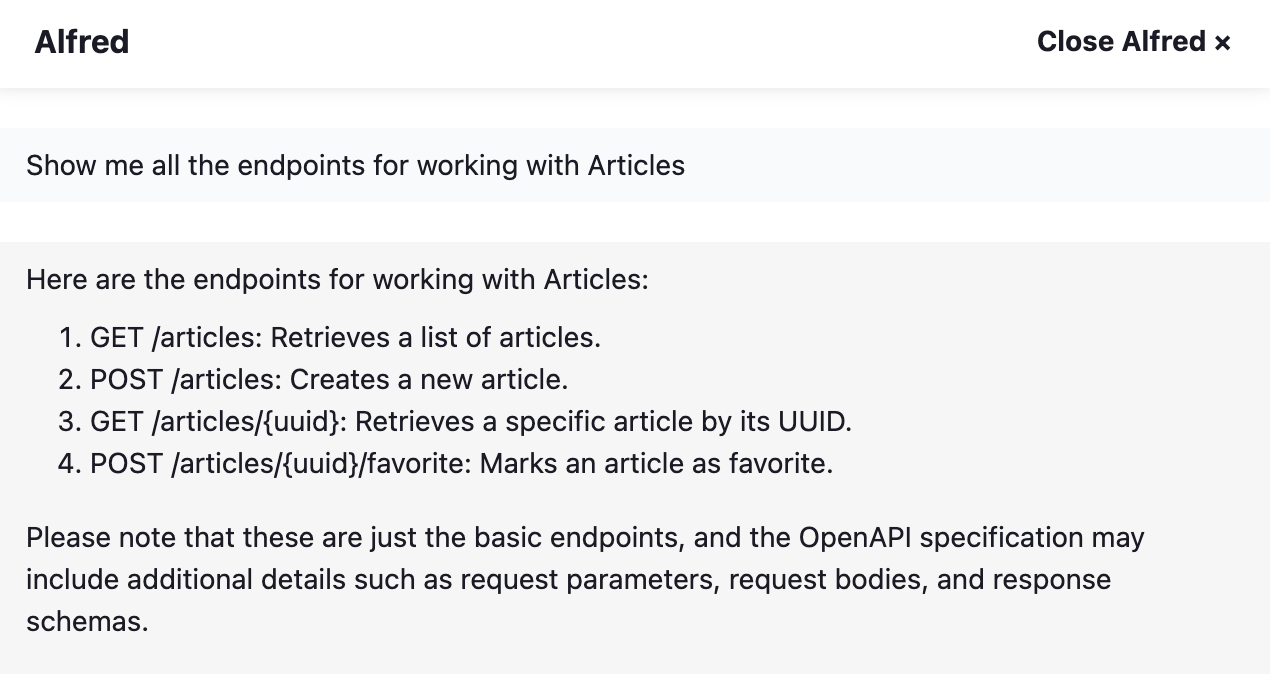
- Show me all the endpoints for working with Articles (it will actually list all the endpoints in that endpoint group and their mandatory parameters)
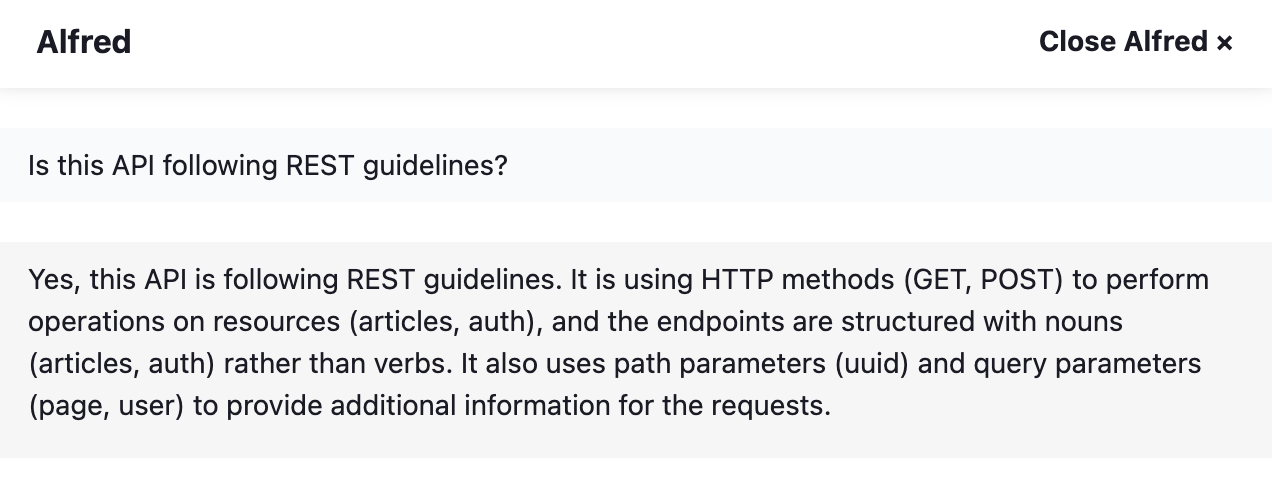
- Is this API following REST guidelines? (it will check to see if the API is following industry standards and best practices when designing and building this API)
API specific code generation
- Generate the User model in SwiftUI (it generates the actually model that you can copy/paste to your SwiftUI project and it takes into account all the fields returned by your API)

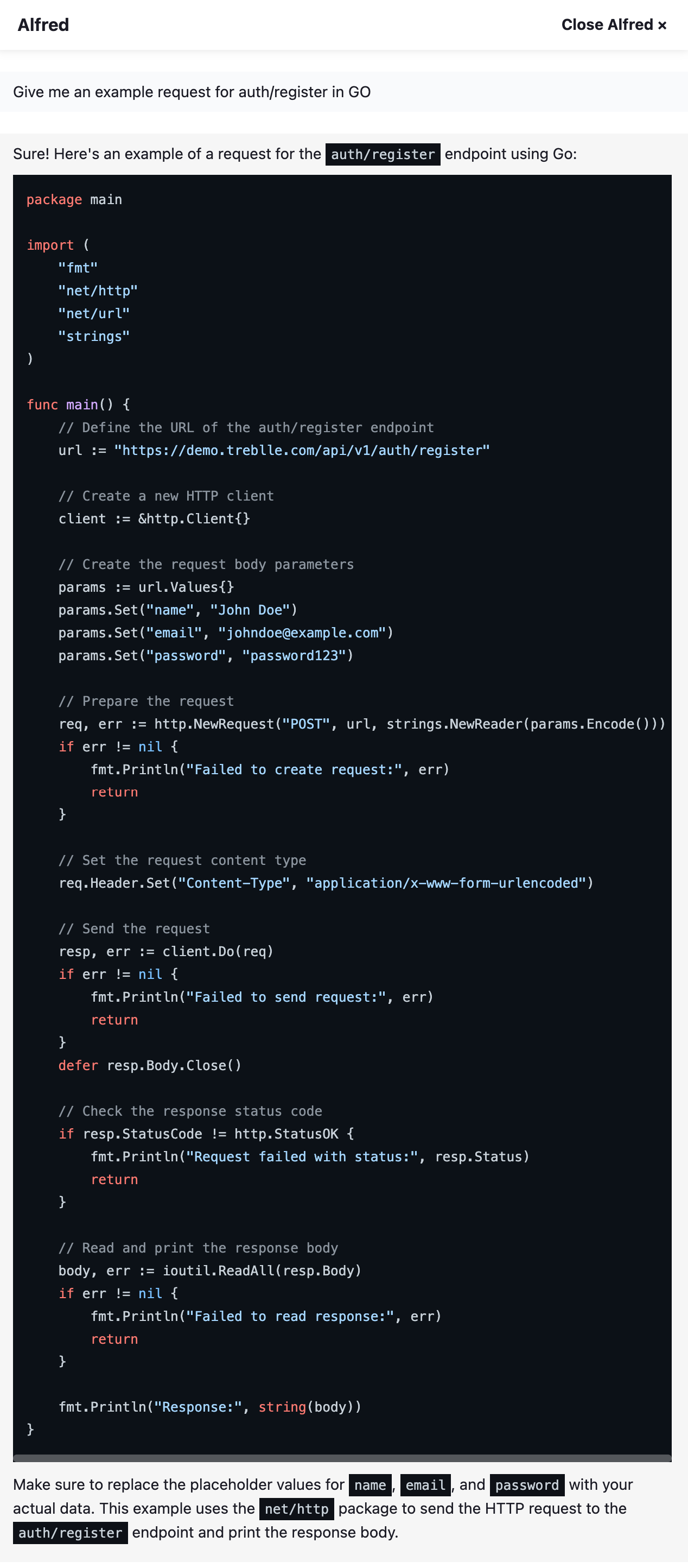
- Give me an example request for auth/register in GO (it shows you the exact code that you need to make a POST request in this case, and it includes all the payload data it sees it needs in order to create a user)
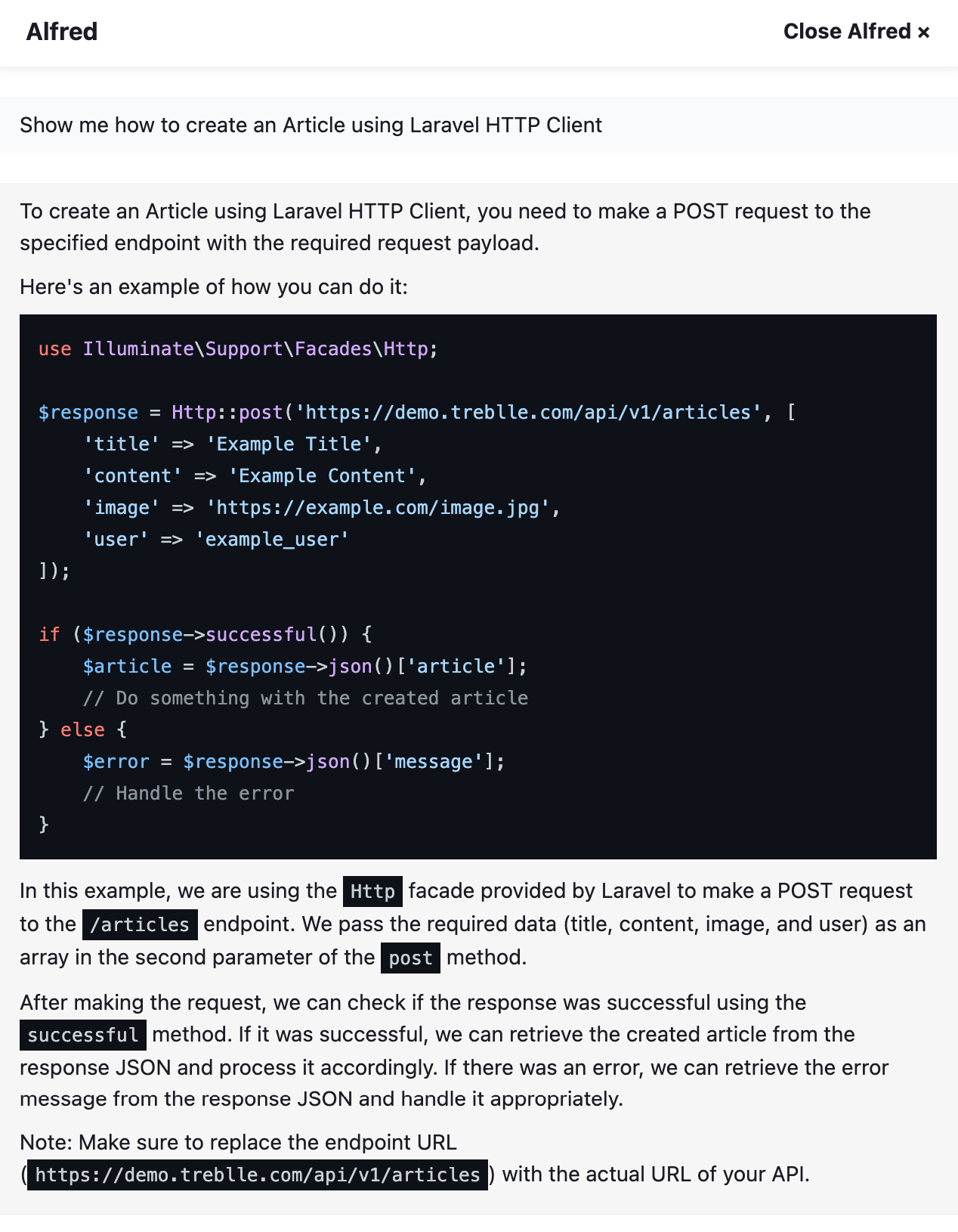
- Show me how to create an Article using Laravel HTTP Client (it understands natural language and knows I want to do a POST request to articles so it shows me the exact code and all the payload details i need to send)
- Generate a test in PHP for the auth/login endpoint (it actually generates a test that checks to see if the response schema matches the one that should be returned by the API)

- Make a POST request to articles using Guzzle, then take the article object and get the uuid value and make another GET request to articles/:uuid (it will make the POST request, take the given returned uuid and pass it to the GET request all in PHP)

I could go on and on with examples but I think you get the point. You can use Alfred to basically never have to read a line of documentation ever again and generate all the boilerplate code you need to use this API. Just think about it: your mobile engineering teams can generate models and code to make requests, your partners can build SDKs and integrations to your API faster, you can improve the developer experience for your internal teams, you can reduce time to first call and integration by 10x. All you have to do is build the API and we’ll document it and allow others to get started using it much faster.
To wrap things up: AI is here and it’s not going anywhere, anytime soon. The beauty of services like OpenAI and Bard is that they allow everyone to build new experiences on top of them. What makes Alfred special and why it’s so magical is the combination of your data and generative AI. So the future will be kind to folks who hold the data or the ones who build the services.




